java
rocketmq
3d
WS2812 5050 RGB
wpf
题解
flink
RK3399
关键路径
TCP/UDP
文件
规范
离线仿真项目
移动魔百盒
责任链模式
跨境电商
redux
多版本并发控制机制
太空工程师
推荐
beautifulsoup
2024/4/11 16:00:30
HTML页面解析概述:使用Python和BeautifulSoup
工具下载链接:https://pan.quark.cn/s/15c0b553b6b8
HTML页面解析是网络爬虫的核心任务之一,它涉及到提取HTML文档中的数据。在这篇博客文章中,我们将介绍如何使用Python和BeautifulSoup库来解析HTML页面,并提取我们需要的信息。…

使用BeautifulSoup 4和Pillow合并网页图片到一个PDF:一种高效的方式来处理网页图像
背景
网页上的培训材料,内容全是PPT页面图片。直接通过浏览器打印,会存在只打印第一页,并且把浏览器上无效信息也打印出来情况。但目标是希望将页面图片全部打印为pdf形式。 实现方案
利用网页“另存为”,将页面内所有图片资…
爬取知乎热搜榜前十条数据
效果如下 代码如下
import requests
from bs4 import BeautifulSoup
import csv# 发送HTTP请求,获取知乎热搜榜页面内容
url https://www.zhihu.com/billboard
response requests.get(url)
html_content response.text# 解析HTML内容
soup BeautifulSoup(html_…
Python beautifulsoup模块简介及安装
视频版教程:一天掌握python爬虫【基础篇】 涵盖 requests、beautifulsoup、selenium
简单来说,Beautiful Soup 是 python 的一个库,最主要的功能是从网页抓取数据。官方解释如下:
Beautiful Soup 提供一些简单的、python 式的函…
python代码小tips-从HTML字符串中提取文本内容并去掉标签
从类似HTML格式的字符串中提取文本内容并去掉标签,可以使用Python的 BeautifulSoup 库,这是一个用于解析HTML和XML的强大工具。首先,确保已经安装了 BeautifulSoup,可以使用以下命令来安装它:
pip install beautifuls…

Python数据采集实战-使用BeautifulSoup框架解析HTML文档并提取所需内容(附源码和实现效果)
实现功能
使用BeautifulSoup框架解析HTML文档并提取所需内容的例子:假设我们要从以下HTML文档中提取所有超链接的链接地址
实现代码 from bs4 import BeautifulSoup
import requests# 发送请求并获取HTML文档
url "https://www.baidu.com"
response r…
大麦订单生成器最新版 大麦订单一键生成截图
1.可以一键添加,生成的假订单没有水印,界面也很真实。
2.在软件中输入生成的信息,这是产品信息,选择生成的产品图像,最后生成它。 后台一键生成,独立后台管理
教程:解压源码,修改数…
爬虫--爬取自己想去的目的的车票信息
前言:
本篇文章主要作为一个爬虫项目的小练习,来给大家进行一下爬虫的大致分析过程以及来帮助大家在以后的爬虫编写中有一个更加清晰的认识。
一:环境配置
Python版本:3.7
IDE:PyCharm
所需库:requests࿰…
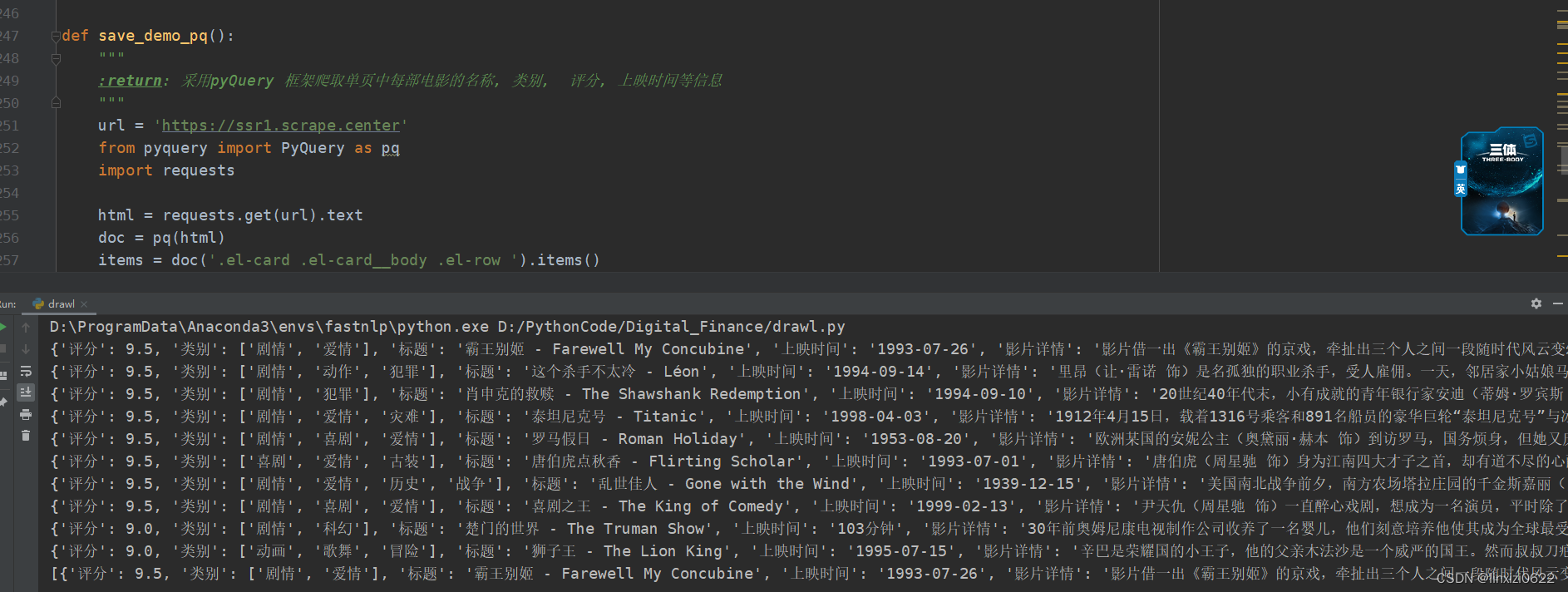
采用BeautifulSouppqQueryxpath三种方法爬取电影详情页
采用三个框架BeautifulSoup&&pqQuery&&xpath,爬取知名的电影网页
主要是想体验这三种框架爬同一个网页的不同。
当然具体的不同我也说不清道不明 只能是体验了一把
以下代码都是本人亲自撸 如图所示,四个位置。分别爬取 电影名字 -&g…
第二章:25+ Python 数据操作教程(第二十五节用 PYTHON 和 R 制作祝福圣诞节)持续更新
这篇文章献给所有 Python 和 R 编程爱好者...通过以下程序在同行中炫耀您的知识。作为一名数据科学专业人士,您希望自己的愿望在圣诞节前夕变得特别。如果您观察代码,您还可以学到 1-2 个技巧,您可以在以后的日常任务中使用这些技巧。 方法 1:运行以下程序,看看我的意思 R…

爬虫入门到精通_基础篇4(BeautifulSoup库_解析库,基本使用,标签选择器,标准选择器,CSS选择器)
1 Beautiful说明
BeautifulSoup库是灵活又方便的网页解析库,处理高效,支持多种解析器。利用它不用编写正则表达式即可方便地实线网页信息的提取。
安装
pip3 install beautifulsoup4解析库
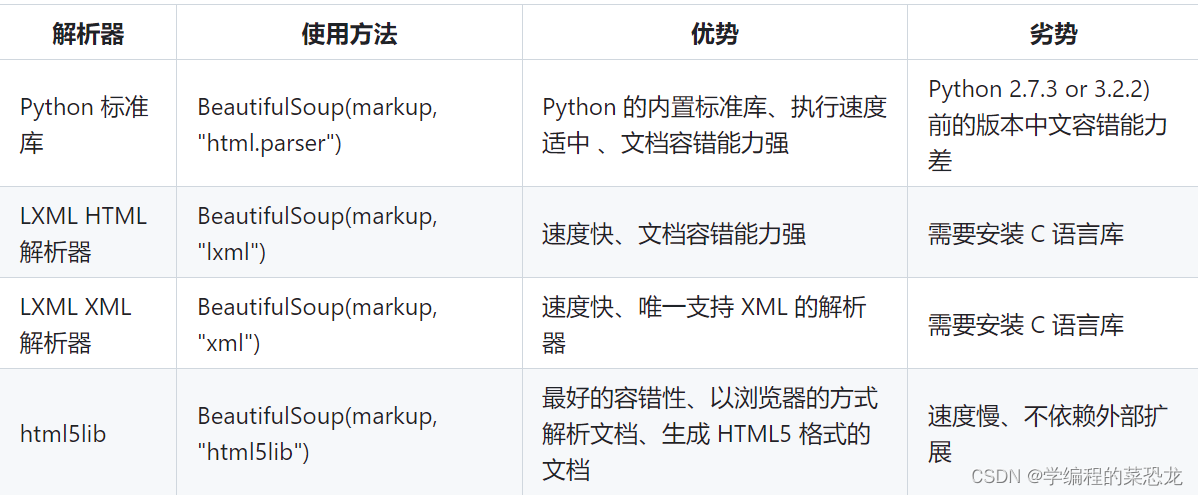
解析器使用方法优势劣势Python标准库BeautifulSoup(markup,…
Python 网页解析高级篇:深度掌握BeautifulSoup库
在Python的网络爬虫中,BeautifulSoup库是一个强大的工具,用于解析HTML和XML文档并提取其中的数据。在前两篇文章中,我们已经讨论了BeautifulSoup库的基本和中级使用方法,但BeautifulSoup的能力远远超出了这些。在这篇文章中&#…
第一章:最新版零基础学习 PYTHON 教程(第四节 - Python 3 基础知识)
Python 3 是一种流行的高级编程语言,用于各种应用程序。以下是您应该了解的一些 Python 3 基础知识: 变量:在 Python 3 中,变量是通过将值分配给名称来创建的。例如,x 5 创建一个名为 x 的变量,并为其分配…
第七章:最新版零基础学习 PYTHON 教程—Python 列表(第三节 -Python程序访问列表中的索引和值)
有多种方法可以访问列表的元素,但有时我们可能需要访问元素及其所在的索引。让我们看看访问列表中的索引和值的所有不同方法。
目录
使用Naive 方法访问列表中的索引和值
使用列表理解访问列表中的索引和值
第九章:最新版零基础学习 PYTHON 教程—Python 元组(第三节 -访问Python元组的前后元素)
有时,在处理记录时,我们可能会遇到需要访问特定记录的初始数据和最后数据的问题。此类问题可以在许多领域中应用。让我们讨论一些可以解决这个问题的方法。
目录
Python3
Python3
Python3
Python3
Python3
Python3
Python3 方法#1:使用访问括号我们可以使用访问括号…
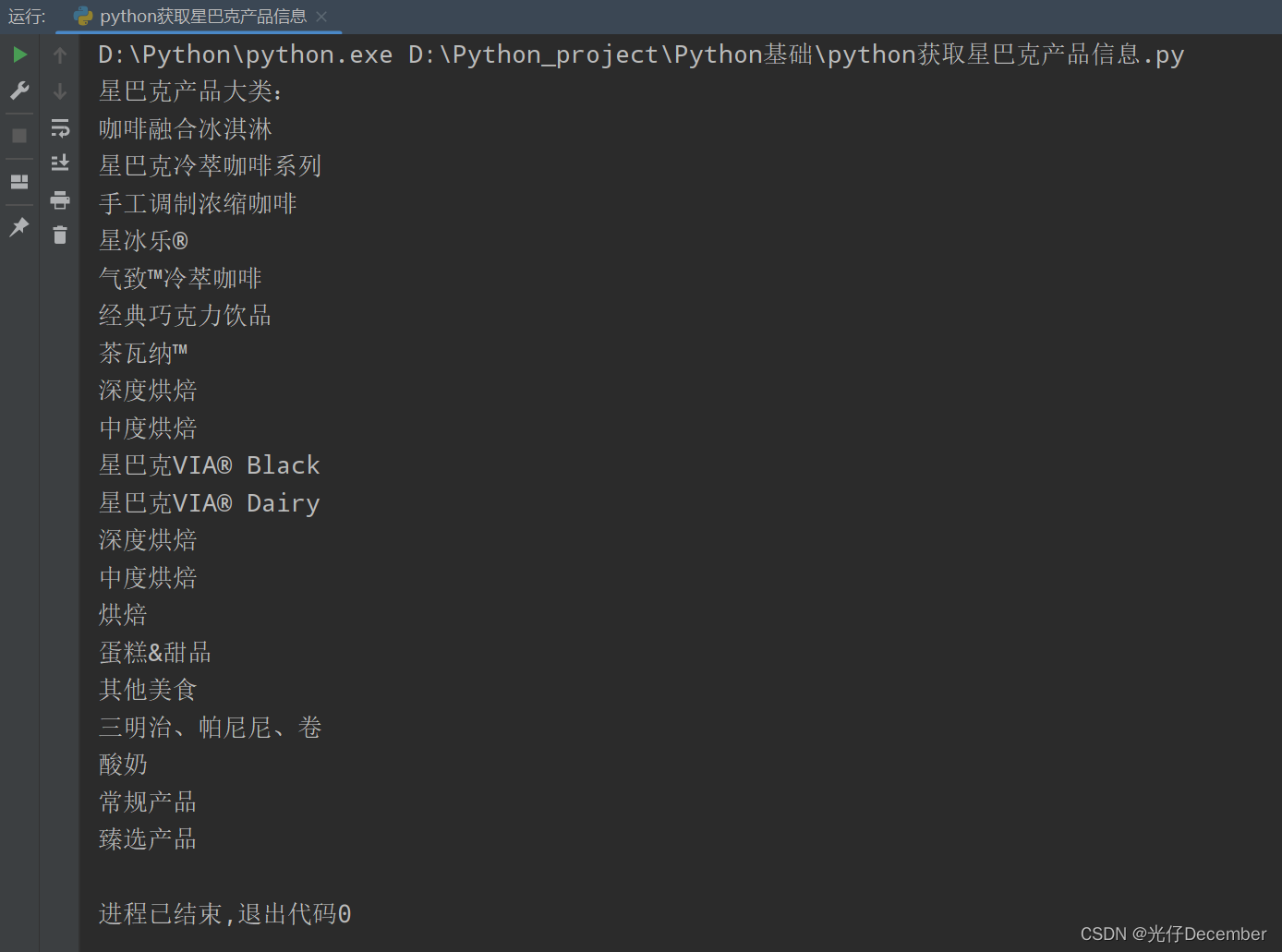
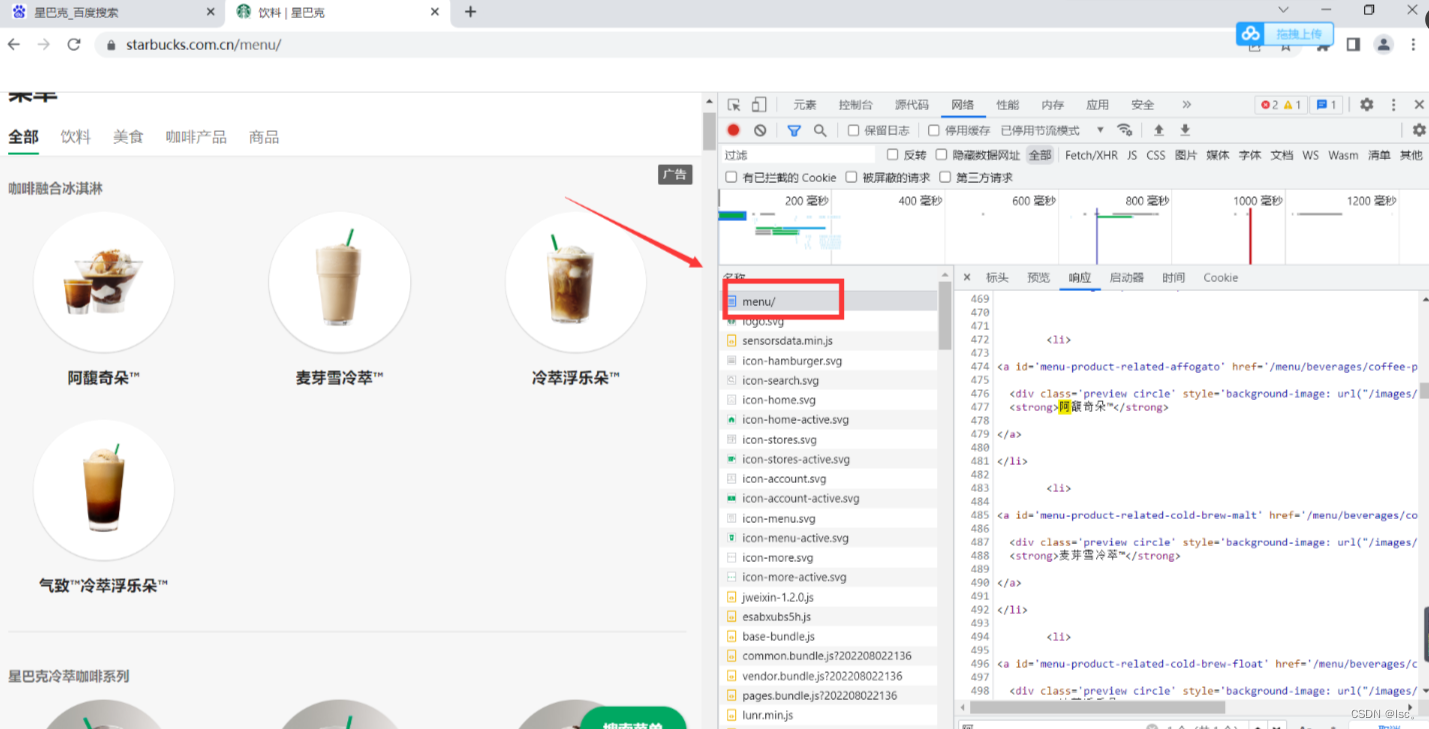
【Python从入门到进阶】33、使用bs4获取星巴克产品信息
接上篇《32、bs4的基本使用》 上一篇我们介绍了BeautifulSoup的基本概念,以及bs4的基本使用,本篇我们来使用bs4来解析星巴克网站,获取其产品信息。
一、星巴克网站介绍 星巴克官网是星巴克公司的官方网站,用于提供关于星巴克咖啡…
Python 实现网络爬虫
爬虫(Web crawler)是一种自动抓取互联网信息的程序。它可以自动获取网页数据并进行处理,是搜索引擎、数据挖掘、信息聚合等应用的基础。爬虫的基本工作流程如下:
指定一个或多个目标网站获取网站的首页数据解析首页数据中的链接&…
BeautifulSoup 用法详解 —— 搜索文档树 find() 和 find_all()
Beautiful Soup 4.4.0 文档: https://beautifulsoup.readthedocs.io/zh_CN/latest/
1. find_all()
find_all(name, attrs, recursive, string, **kwargs)
find_all() 方法搜索当前 tag 的所有子节点,并判断是否符合过滤器的条件:
soup.…
Python 网页解析中级篇:深入理解BeautifulSoup库
在Python的网络爬虫中,BeautifulSoup库是一个重要的网页解析工具。在初级教程中,我们已经了解了BeautifulSoup库的基本使用方法。在本篇文章中,我们将深入学习BeautifulSoup库的进阶使用。
一、复杂的查找条件
在使用find和find_all方法查找…
BeautifulSoup 用法详解 —— 遍历文档树
Beautiful Soup 4.4.0 文档: https://beautifulsoup.readthedocs.io/zh_CN/latest/
1. 子节点
一个 Tag 可能包含多个字符串或其它的 Tag,这些都是这个 Tag 的子节点。BeautifulSoup 提供了许多操作和遍历子节点的属性。
操作文档树最简单的方法就是…

文件高效批量重命名,轻松重命名不同类型的文件名并隐藏编号
你是否曾经因为文件名混乱而感到困扰?你是否希望有一种方法可以快速、简单地管理你的文件名?如果你的答案是肯定的,那么我们的产品——文件重命名工具,将是你的完美解决方案!
首先我们要进入文件批量改名高手主页面&a…
python双色球-(一)采集双色球历史数据
多年之后,再次感受双色球的魅力,芸芸众生都为之倾倒,但是温馨提示:赌博有风险,本文仅做数据处理技术讨论,不构成任何资金投入建议!
现如今的IT行业竞争越来越激烈,一线大厂都是各种…
第五章:最新版零基础学习 PYTHON 教程—Python 字符串操作指南(第五节 - 在Python中打印转义字符的方法)
转义字符是通常用于执行某些任务的字符,它们在代码中的使用指示编译器采取映射到该字符的适当操作。例子 : \n --> 留下一行 \t --> 留一个空格 目录 使用 repr() 使用“r/R”
最新大麦订单生成器 大麦订单图一键生成
1、8.6全新版 本次更新了四种订单模板生成 多模板自由切换 2、在软件中输入生成的信息,这里输入的是商品信息,选择生成的商品图片,最后生成即可 新版大麦订单生成 四种模板图样式展示 这个样式图就是在大麦生成完的一个订单截图ÿ…
精进Beautiful Soup 小技巧(一)
前言:
对Beautiful Soup已经用了有快3年了,对于一些html等的使用也有一些特殊方法;来一些平时不容易察觉的,但其实很有用的大小! 使用合适的解析器:
实例化BeautifulSoup时,选择合适的解析器,如 html.parser, lxml, 或 html5lib,…
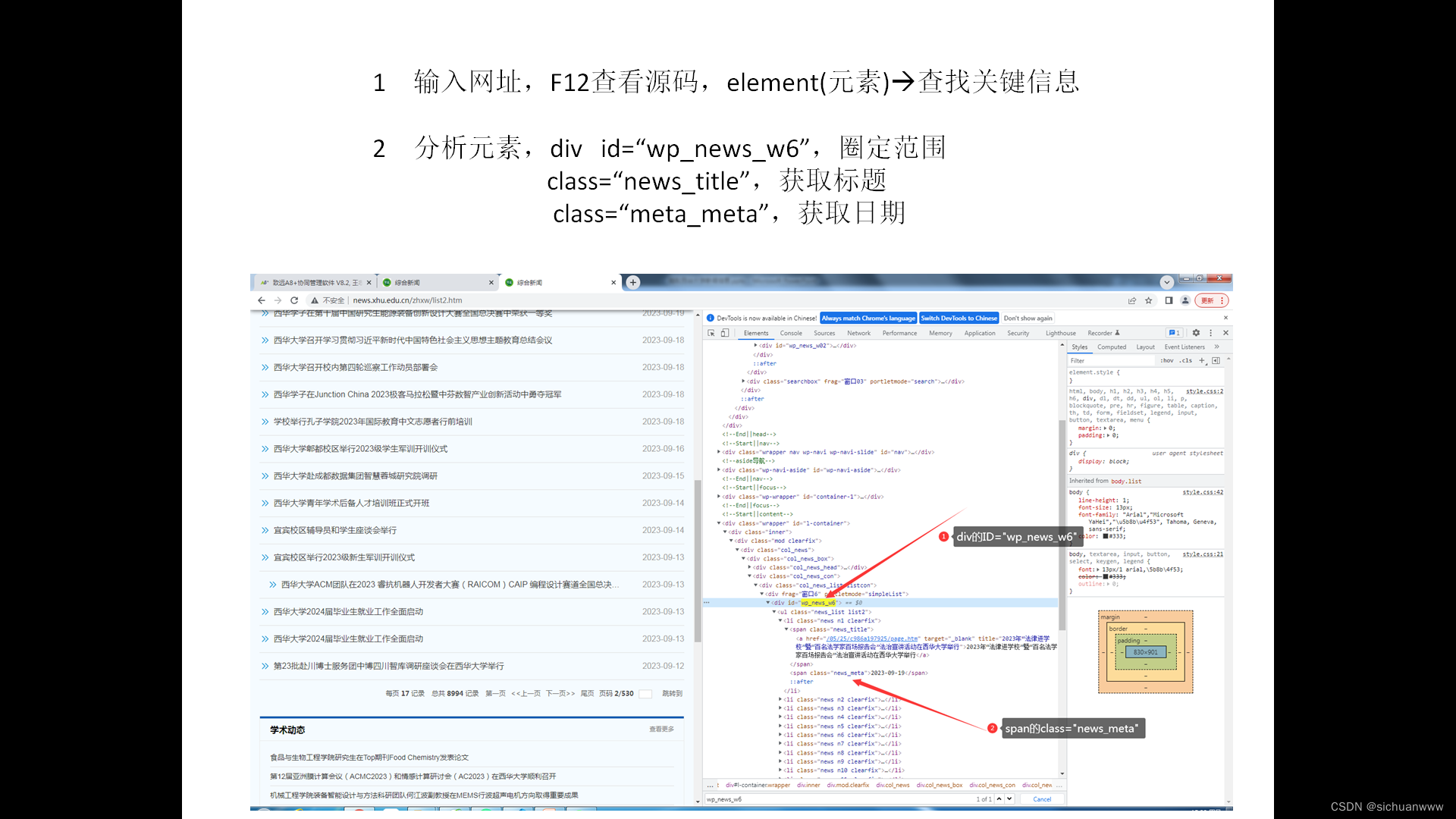
获取西华大学新闻网站信息(爬虫样例)
利用python的爬虫功能进行信息爬取,关键在于源码分析,代码相对简单。
1 源代码分析
访问网站,按下F12,进行元素查找分析。 2 代码实现
from requests import get
from bs4 import BeautifulSoupdef getXhuNews(pageNum1):&qu…
第五章:最新版零基础学习 PYTHON 教程(第一节 - Python 字符串—字符串是 Python 中表示字符序列的数据结构)
字符串是 Python 中表示字符序列的数据结构。它是一种不可变的数据类型,这意味着一旦创建了字符串,就无法更改它。字符串广泛用于许多不同的应用程序,例如存储和操作文本数据、表示名称、地址以及可以表示为文本的其他类型的数据。
Python 中的字符串是什么?
Python没有字…
【爬虫】实验项目二:模拟登录和数据持久化
目录
一、实验目的
二、实验预习提示
三、实验内容
实验要求
基本要求:
改进要求A:
改进要求B:
四、实验过程
基本要求:
源码如下: 改进要求A:
源码如下:
改进要求B:
源码如下&…
6.HTML内容解析-BeautifulSoup4
目录
一、安装BeautifulSoup4
二、导入 BeautifulSoup4
三、生成BeautifulSoup对象
1.解析器
2.requests与BeautifulSoup结合使用
爬虫时如何利用BeautifulSoup获取我们需要的数据?
爬虫大致可以分为三步:
第一步,发送request请求获得html内容第二步,清洗数据,即从html原网页数据中筛选我们需要的数据第三步,将需要的数据储存 在第二步筛选数据是,我们往往可以利用BeautifulSoup来完成&…
Python爬虫---使用BeautifulSoup下载麦当劳点餐图片
步骤:
1. 导入需要使用的包
2. 定位正确的url地址
3. 发请求
4. 获取响应
5. 解析响应的内容
6. 将获取的xpath语法转换成bs4语法
7.下载图片
import urllib.request
from bs4 import BeautifulSoup# url
url "https://www.mcdonalds.com.cn/index/Fo…

爬虫源码---爬取自己想要看的小说
前言:
小说作为在自己空闲时间下的消遣工具,对我们打发空闲时间很有帮助,而我们在网站上面浏览小说时会被广告和其他一些东西影响我们的观看体验,而这时我们就可以利用爬虫将我们想要观看的小说下载下来,这样就不会担…
正则表达式和BeautifulSoup
文章目录 1、正则表达式介绍2、正则表达式和BeautifulSoup3、获取属性4、Lambda表达式 1、正则表达式介绍 正则表达式是指一个用来描述或者匹配一系列符合某个句法规则的字符串的单个字符串。它描述了一种字符串匹配的模式(pattern),可以用来…
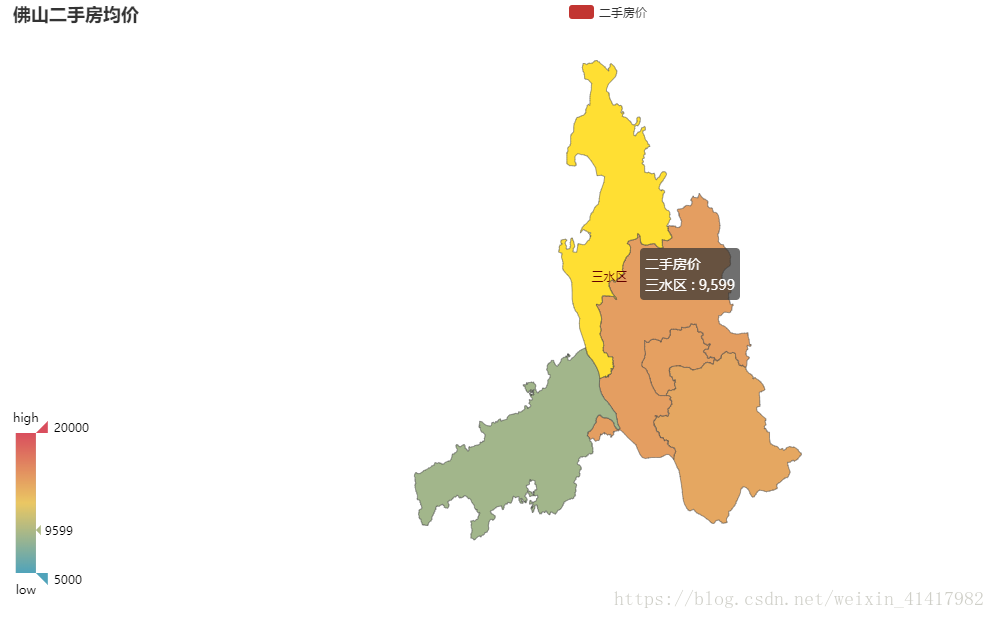
爬虫(一)request和BeautifulSoup
先说明,我也是新手。我也是昨晚突然有兴趣才看的爬虫。我是在知乎找的教程。改动很少(有一句扑街了,我改了)。
主要是想记录理解的东西。Show the Code:
import requests
from bs4 import BeautifulSoupcomments []
r request…

一天掌握python爬虫【基础篇】 涵盖 requests、beautifulsoup、selenium
大家好,我是python222小锋老师。前段时间卷了一套 Python3零基础7天入门实战 以及1小时掌握Python操作Mysql数据库之pymysql模块技术
近日锋哥又卷了一波课程,python爬虫【基础篇】 涵盖 requests、beautifulsoup、selenium,文字版视频版。1…

利用正则表达式, xpath, Beautifulsoup来解析网页
1 使用正则表达式的时候需要导入re模块,这个是python自带的模块,不用下载
1.1正则表达式有许多常用的规则 这里要注意贪婪匹配和非贪婪匹配以及反斜杠转义的问题 1.2 匹配网页的时候有时候要考虑到换行和大小写的问题 遇到匹配换行时要使用修饰符r…
Python beautifulsoup网络抓取和解析cnblog首页帖子数据
视频版教程:一天掌握python爬虫【基础篇】 涵盖 requests、beautifulsoup、selenium
我们抓取下https://www.cnblogs.com/ 首页所有的帖子信息,包括帖子标题,帖子地址,以及帖子作者信息。
首先用requests获取网页文件࿰…
Argumentative structure for English essay
演讲格式可以根据演讲的目的、受众和主题的性质而有所不同,但通常包括以下元素:
1. **前言(Introduction)**: - **开场白(Opening)**: 吸引听众的注意,可以是一个引人入胜的故事、引用、问题或统计数据…
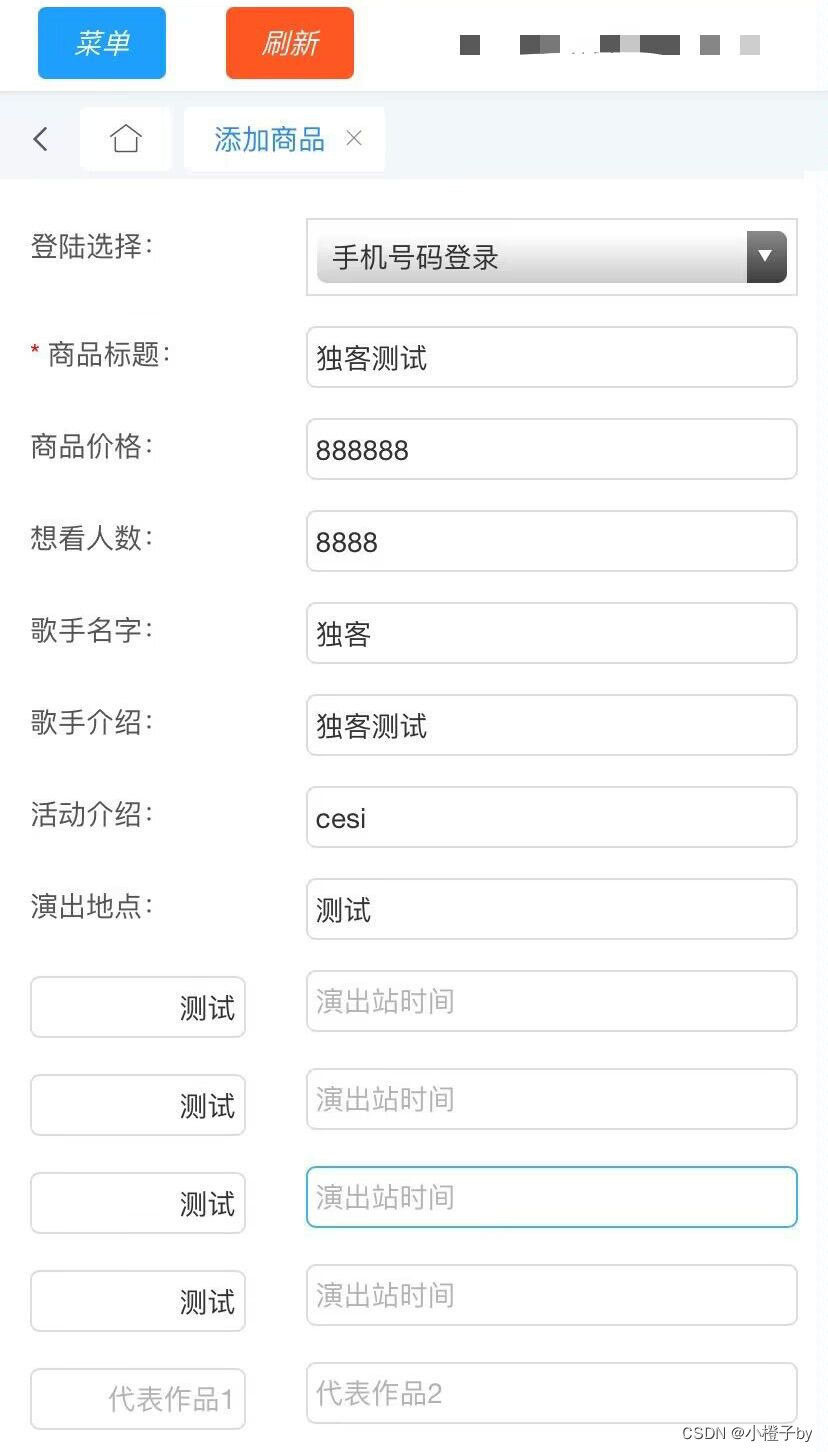
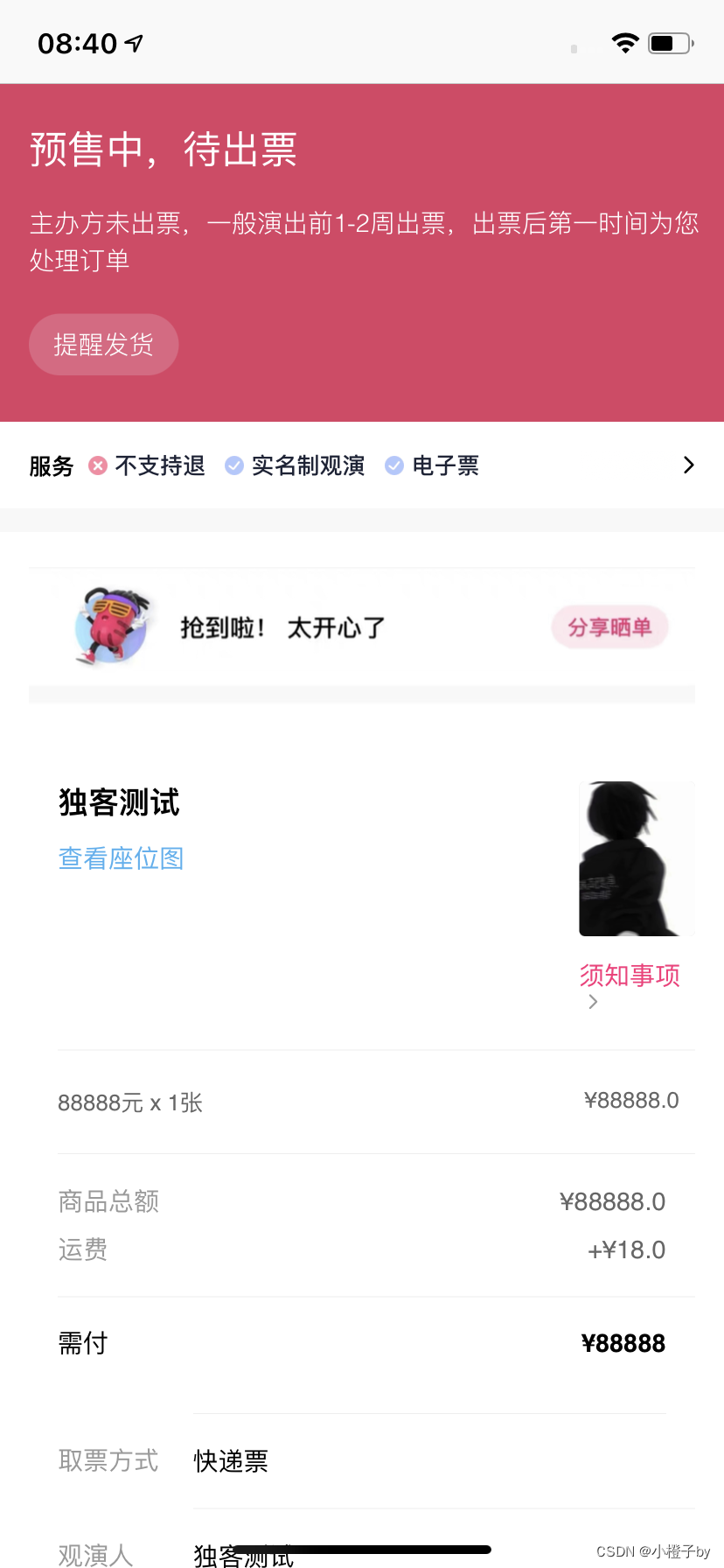
大麦订单截图生成 大麦一键生成订单截图
新版大麦订单生成 图样式展示
这个样式图就是在大麦生成完的一个订单截图,它的状态是等待卖家发货
后台一键生成,独立后台管理
教程:修改conf数据库账号密码 不会的可以看源码里有搭建教程
下载程序:https://pan.baidu.com/…
解析-BeautifulSoup
解析-BeautifulSoup
1.基本简介
1.BeautifulSoup简称:bs4
2.什么是Beatifulsoup?Beautifulsoup,和1xm1一样,是一个html的解析器,主要功能也是解析和提取数据
3.优缺点?缺点: 效率没有1xm1的效率高优点: 接口设计人性化,使用方…

爬虫源码---爬取小猫猫交易网站
前言:
本片文章主要对爬虫爬取网页数据来进行一个简单的解答,对与其中的数据来进行一个爬取。
一:环境配置
Python版本:3.7.3
IDE:PyCharm
所需库:requests ,parsel
二:网站页面 我们需要…
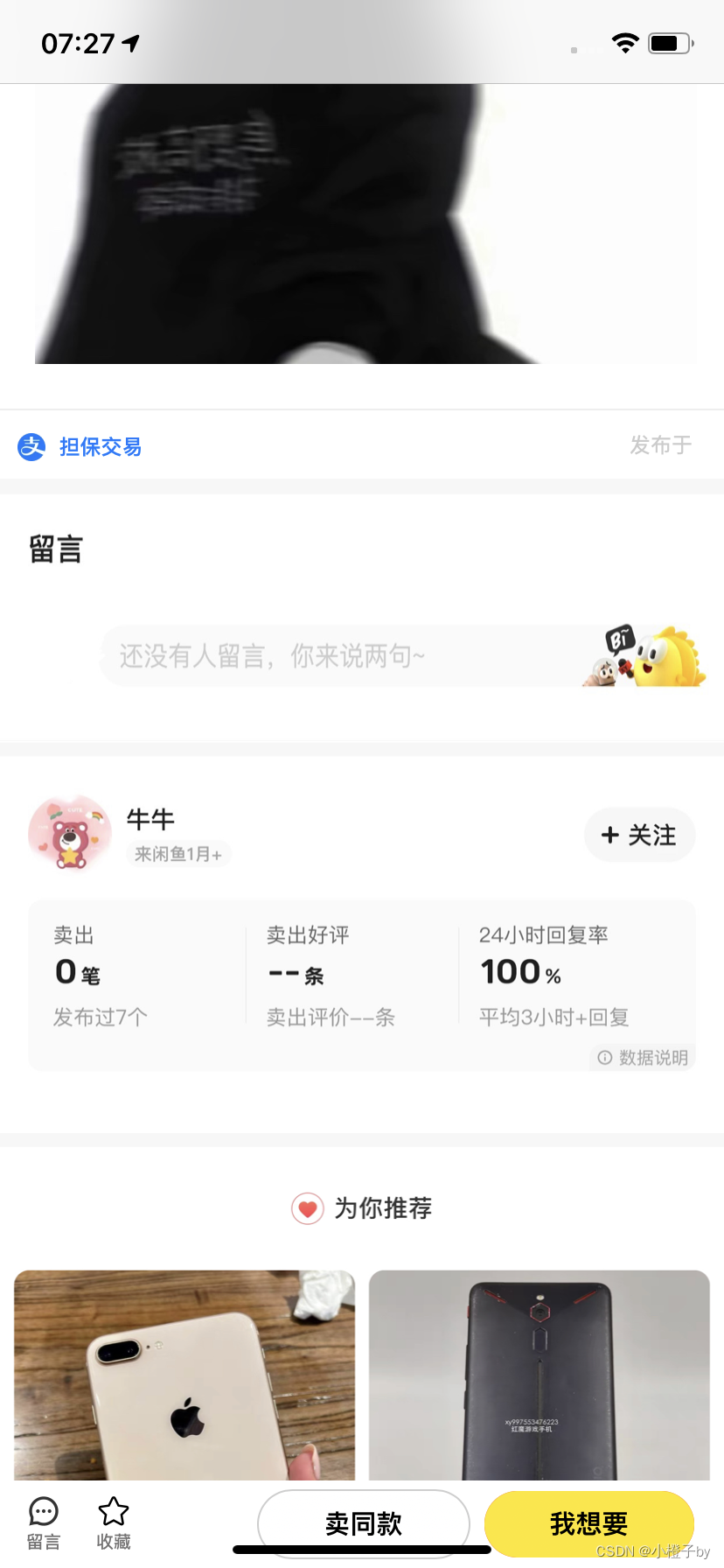
最新仿闲鱼链接+独立后台管理 跳转APP
2024最新仿xy链接源码
后台一键生成链接,后台管理教程:解压源码,修改数据库config/Congig
不会可以看源码里有教程
下载程序:https://pan.baidu.com/s/16lN3gvRIZm7pqhvVMYYecQ?pwd6zw3
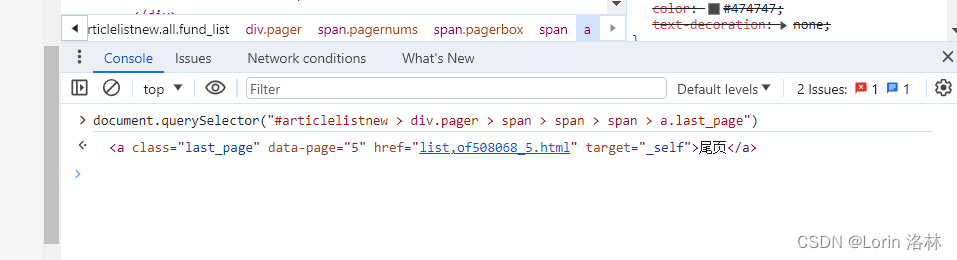
Python BeautifulSoup 选择器无法找到对应元素(异步加载导致)
文章目录 问题原因解决方案找到包含内容的 XHR 异步请求无头浏览器 个人简介 问题
使用 Python BeautifulSoup 爬取一个股吧帖子发现某个样式无法找到,但是在网页中确实存在这个元素:网页使用 document.querySelector 可以正常查找: 但是 Py…
使用爬虫去获取四六级成绩
使用爬虫去获取四六级成绩
今天出成绩,没过,二战六级依然惨死,那么我就写一个简单的爬虫,其实也可以封装成一个接口的,然后直接输入姓名 身份证好 以及四六级即可获取成绩,我就是简单的玩了一下哈…
网络爬虫实践1-爬取百度文库,存入Word文档
本文主要参考文章<使用Selenium爬取百度文库word文章>,在这里要感谢作者的分享。 本文主要就是代码,因为代码里有详细的注释说明。所以,就不再文字描述了。各位看官们,直接看代码和注释吧。
# -*- coding: utf-8 -*-from s…
Python爬虫---解析---BeautifulSoup
BeautifulSoup简称:bs4
作用:解析和提取数据
1. 安装:pip install bs4 或pip install bs4 -i https://pypi.douban.com/simple(使用国内镜像下载)
注意:需要安装在python解释器相同的位置,例如…
【爬虫】实验项目一:文本反爬网站的分析和爬取
一、实验目的 熟悉使用Selenium、Pyppeteer等工具爬取网站基本内容,通过分析具有文本反爬技术网站,设计爬取策略来获取文本正确的内容。 二、实验预习提示
安装Python环境 (Python 3.x):PychramAnaconda为Python安装S…
使用Python的学生信息管理系统
import re # 导入正则表达式模块
import os # 导入操作系统模块filename "students.txt" # 定义保存学生信息的文件名def menu():# 输出菜单print(╔————————————————学生信息管理系统—————————————————╗│ …
大麦订单生成 大麦订单购票成功截图生成
后台一键生成链接,后台管理
教程:解压源码,修改数据库config/Congig
不会可以看源码里有教程
下载程序:https://pan.baidu.com/s/16lN3gvRIZm7pqhvVMYYecQ?pwd6zw3
BeautifulSoup模块基本使用方法(解析—提取数据)
一、了解BeautifulSoup
1、简介
一个灵活又方便的网页解析库,最主要的功能是从网页抓取数据,处理高效,支持多种解析器,
它通过转换器实现文档导航、查找、修改文档的方式。利用它可不用编写正则也能方便的实现网页信息的抓取&am…

python爬虫request和BeautifulSoup使用
request使用
1.安装request
pip install request2.引入库
import requests3.编写代码
发送请求
我们通过以下代码可以打开豆瓣top250的网站
response requests.get(f"https://movie.douban.com/top250")但因为该网站加入了反爬机制,所以…
Python爬虫:BeautifulSoup之搜索文档树
搜索文档树
1、前面介绍了BeautifulSoup库的基本使用:可通过"BeautifulSoup对象.标签名"来获取指定的Tag对象 ⑴只是使用这种方法来获取标签对象时,只会返回第一个匹配的标签对象
2、另外BeautifulSoup库还提供了其他方法来获取某一标签对象。其中经常使用到…
通过BeautifulSoup获取【领域赛道--大数据与算法】top100用户
文章目录 前言介绍实现帖子地址请求地址引入模块提取代码程序入口提取到的数据 总结最后 前言
博主空空star主页空空star的主页 大家好,我是空空star,本篇给大家分享一下《通过BeautifulSoup获取【领域赛道--大数据与算法】top100用户》。 介绍 Beautif…
Python|爬虫和测试|selenium框架模拟登录示例(一)
前言: 上一篇文章Python|爬虫和测试|selenium框架的安装和初步使用(一)_晚风_END的博客-CSDN博客 大概介绍了一下selenium的安装和初步使用,主要是打开某个网站的主页,基本是最基础的东西,那么,…
Python爬虫利器:BeautifulSoup库详解
BeautifulSoup是Python中最流行的HTML解析库之一,它可以方便地从HTML文档中提取数据,并且支持多种解析器,可以适应不同的HTML文档格式。本文将介绍BeautifulSoup库的作用、用途和基本用法,帮助读者了解如何使用BeautifulSoup进行H…

转转闲鱼交易猫链接源码 支持二维码收款
最新仿二手闲置链接源码
后台一键生成链接,后台管理教程:解压源码,修改数据库config/Congig
不会可以看源码里有教程
下载程序:https://pan.baidu.com/s/16lN3gvRIZm7pqhvVMYYecQ?pwd6zw3

爬虫入门指南(7):使用Selenium和BeautifulSoup爬取豆瓣电影Top250实例讲解【爬虫小白必看】
文章目录 介绍技术要点SeleniumBeautifulSoupOpenpyxl 实现步骤:导入所需库设置网页URL和驱动路径创建 ChromeDriver 服务配置 ChromeDriver创建 Excel 文件爬取数据关闭浏览器保存 Excel 文件 完整代码导出的excel 效果图未完待续.... 介绍
在本篇博客中ÿ…

老鱼Python数据分析——篇十二:使用selenium+BeautifulSoup获取淘股吧数据
在淘股吧发现有位大牛每天都有数据整理,地址:湖南人的博客
所以直接下载他的博客文章即可。
分析发现,他复盘的数据都是使用的图片,所以只需要把博客文章里面的图片下载到本地。
第一步:分析首页数据: 通…
BeautifulSoup文档5-详细方法 | 修改文档树应该注意什么?
5-详细方法 | 修改文档树应该注意什么?1 修改tag的名称和属性2 修改 .string3 append()4 NavigableString() 和 .new_tag()5 insert()6 insert_before() 和 insert_after()7 clear()8 其他几个方法9 本文涉及的源码BeautifulSoup本身最强大的功能是文档树的搜索&…
【Python】从入门到上头—Python基础(2)
文章目录 一.基础语法1.编码2.标识符3.保留字4.注释5.行与缩进6.多行语句7.数字(Number)类型8.字符串(String)9.空行10.等待用户输入11.同一行显示多条语句12.多个语句构成代码组13.print 输出14.import 与 from...import 二.基本数据类型1.变量和赋值2.多个变量赋值3.标准数据…
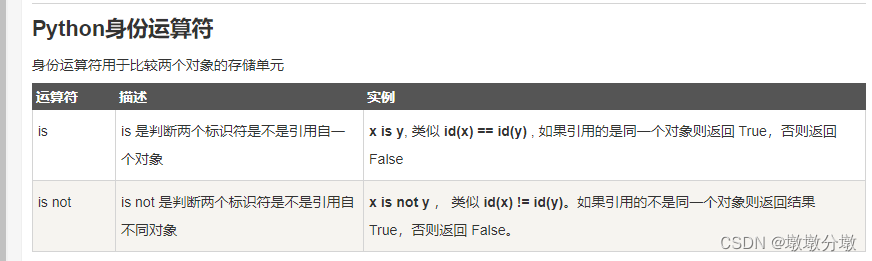
第三章:最新版零基础学习 PYTHON 教程(第六节 - Python 运算符—Python 中的赋值运算符)
运算符用于对值和变量执行操作。这些是执行算术、逻辑、按位计算的特殊符号。运算符运算的值称为操作数。
目录
(1) 赋值:该运算符用于将表达式右侧的值赋给左侧操作数。
Python3
python解析网站BeautifulSoup
首先了解一下正则表达式解析网站
正则表达式是解析网站时必须要了解的,我们在提取网页中的数据时,可以先将源代码变成字符串,然后用正则表达式匹配想要的数据
模式描述.匹配任意字符,除了换行符*匹配前一个字符0次或多次匹配前一…
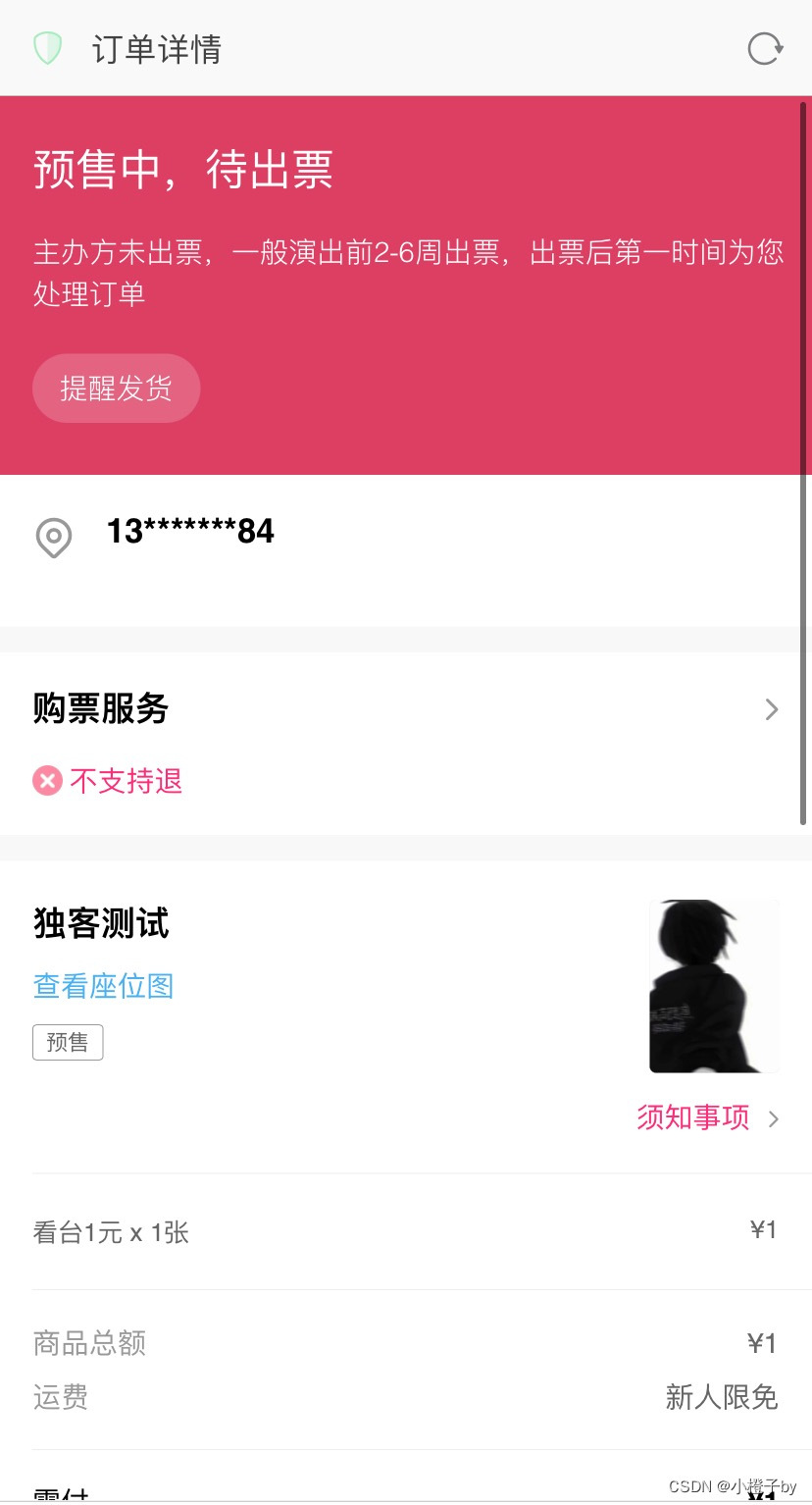
大麦订单截图 一键生成订单截图
新版付款图样式展示
这个样式图就是在大麦刚付款完的一个订单截图,它的状态是等待卖家发货
下滑下载源码 下载源码:https://pan.baidu.com/s/16lN3gvRIZm7pqhvVMYYecQ?pwd6zw3
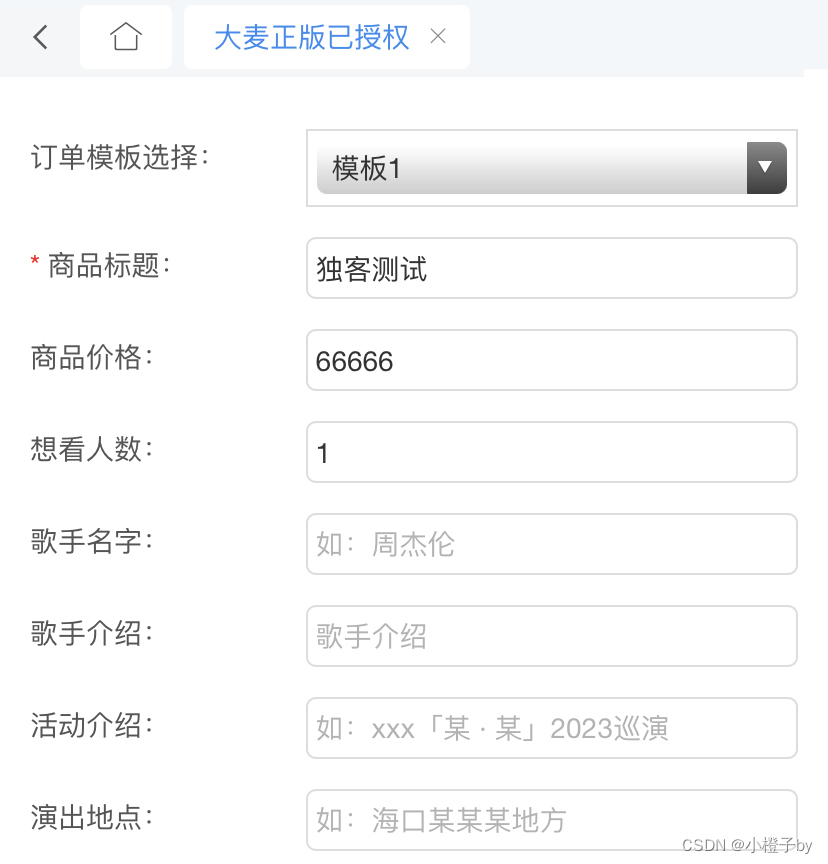
大麦抢票订单生成 大麦订单一键生成 大麦订单截图
1、能够一键的进行添加,生成的假订单是没有水印的,界面也很真实。
2、在软件中输入生成的信息,这里输入的是商品信息,选择生成的商品图片,最后生成即可。
新版大麦订单生成 图样式展示
这个样式图就是在大麦生成完…
Beautifulsoup解析库使用实际案例
爬虫,是学习Python的一个有用的分支,互联网时代,信息浩瀚如海,如果能够便捷的获取有用的信息,我们便有可能领先一步,而爬虫正是这样的一个工具。之前的的文章中讲到了很多有关爬虫基础知识的使用࿰…
python requests爬取税务总局税案通报、税务新闻和政策解读
文章目录 环境配置页面爬取流程税案通报爬取code税务新闻爬取政策解读爬取 环境配置
python:3.7 requests:发出请求,返回页面 beautifulsoup:解析页面 time:及时 warnings:忽视警告
页面
网址࿱…
Beautiful Soup4爬虫速成
做毕业论文需要收集数据集,我的数据集就是文本的格式,而且是静态页面的形式,所以只是一个简单的入门。动态页面的爬虫提取这些比较进阶的内容,我暂时没有这样的需求,所以有这类问题的朋友们请移步。 如果只是简单的静态…
Python beautifulsoup解析本地文件之基础语法
视频版教程:一天掌握python爬虫【基础篇】 涵盖 requests、beautifulsoup、selenium
beautifulsoup支持解析本地文件和网络文件,需要注意的是在实例化 BeautifulSoup 对象时,“html.parser” 是一个解析器,用于解析 HTML 代码&am…
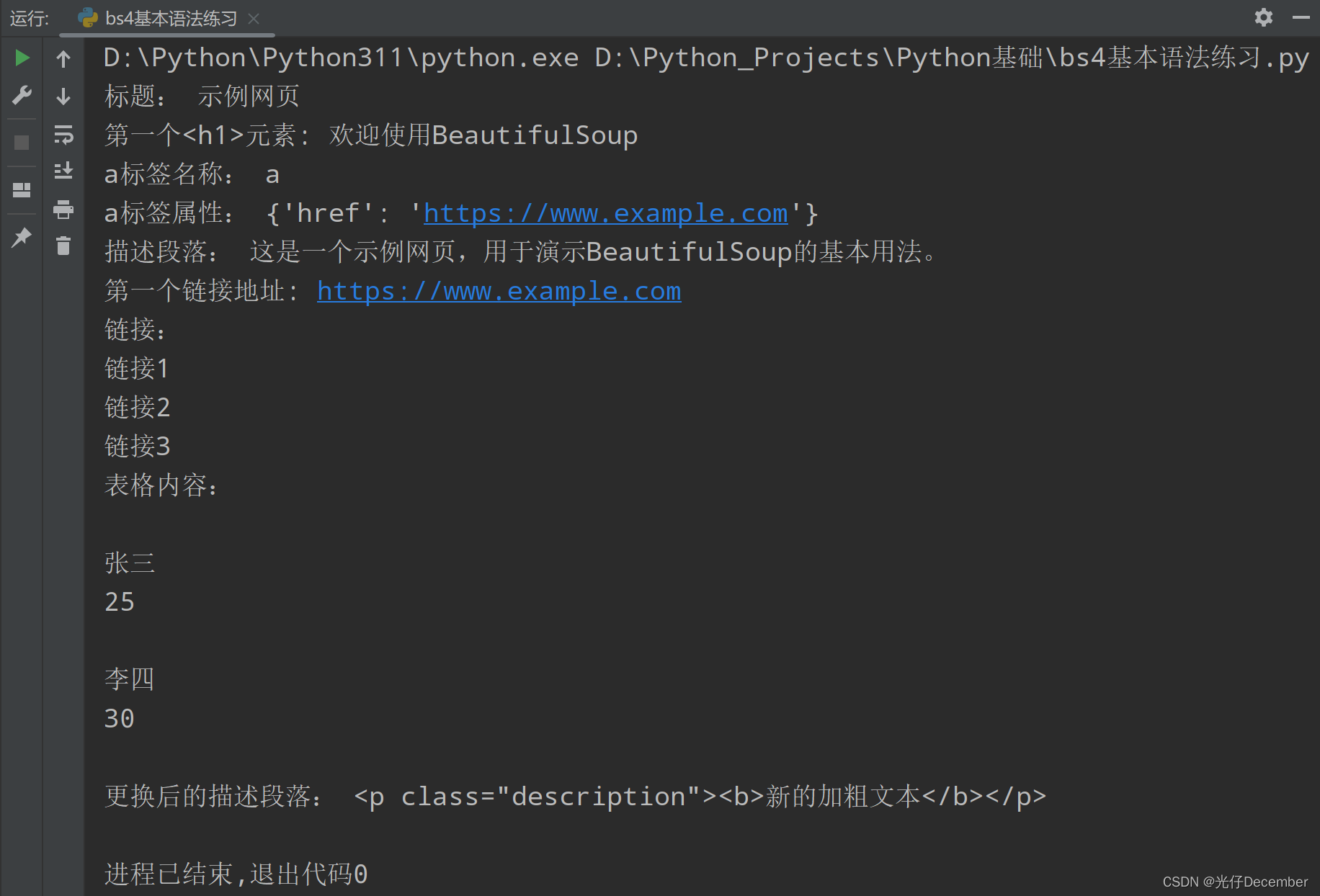
【Python从入门到进阶】32、bs4的基本使用
接上篇《31、使用JsonPath解析淘票票网站地区接口数据》 上一篇我们介绍了如何使用JSONPath来解析淘票票网站的地区接口数据,本篇我们来学习BeautifulSoup的基本概念,以及bs4的基本使用。
一、BeautifulSoup简介
1、bs4基本概念
BeautifulSoup是一个P…
第二章:25+ Python 数据操作教程(第十六节PYTHON 列表理解:通过示例学习)持续更新中
本教程介绍列表理解在 Python 中的工作原理。它包含许多示例,可以帮助您熟悉这个概念,并且您应该能够在本课程结束时在您的实际项目中实现它。
目录
什么是列表理解?
列表推导式 vs. For 循环 vs. Lambda + map()
列表理解:IF-ELSE
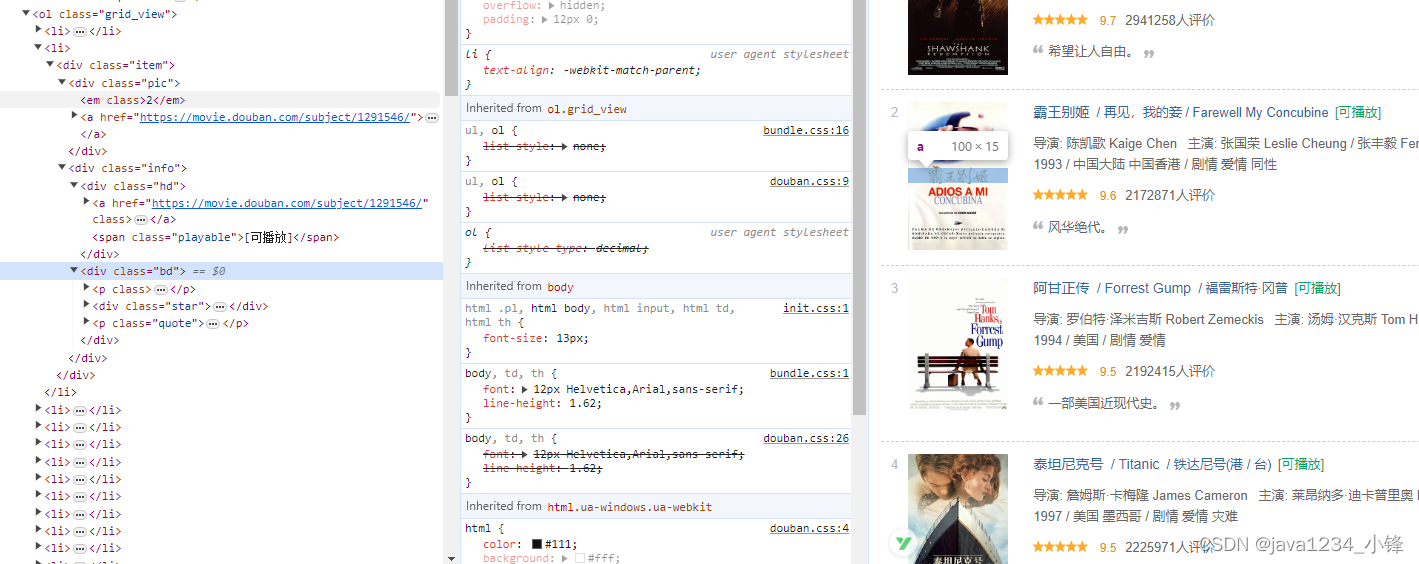
Python爬虫实战-批量爬取豆瓣电影排行信息
大家好,我是python222小锋老师。
近日锋哥又卷了一波Python实战课程-批量爬取豆瓣电影排行信息,主要是巩固下Python爬虫基础
视频版教程:
Python爬虫实战-批量爬取豆瓣电影排行信息 视频教程_哔哩哔哩_bilibiliPython爬虫实战-批量爬取豆瓣…

Python数据分析:beautifulsoup解析网页
Python数据分析:beautifulsoup解析网页
BeautifulSoup 用于解析HTML或XML 步骤 创建BeautifulSoup对象 查询节点 find 找到第一个满足条件的节点 find_all 找到所有满足条件的节点
创建对象 创建BeautifulSoup对象 bs BeautifulSoup( url, html_parse…

BeautifulSoup详解
文章目录1.下载安装2.导入3.装载HTML文档4.将文档数转换成字符串格式5.BeautifulSoup查找文档元素6.BeautifulSoup遍历文档树7.BeautifulSoup使用css语法查找元素9.字符编码问题8.实例:爬取中国天气网数据兰州7天的1.下载安装
pip install bs42.导入
from bs4 imp…

chatgpt赋能python:PythonTables:为你的数据处理带来更高效的解决方案
Python Tables:为你的数据处理带来更高效的解决方案
Python是一种功能强大且易于使用的编程语言,可以用于各种用途。对于数据处理和分析来说,Python是一个非常受欢迎的选择,因为它有许多强大的库和工具可以使用。其中一个很有用的…

摸鱼工具—终端热搜榜,实在是上班摸鱼必备之工具,妙啊
本文介绍我用Python语言开发的热搜榜,聚合有百度、头条、微博、知乎和CSDN等网站热搜信息。该工具运行于终端中,比如cmder、powershell或者git bash等,实在是上班、摸鱼之必备工具。
—、工具执行效果 1.1 项目代码
项目代码地址存在gitee中…
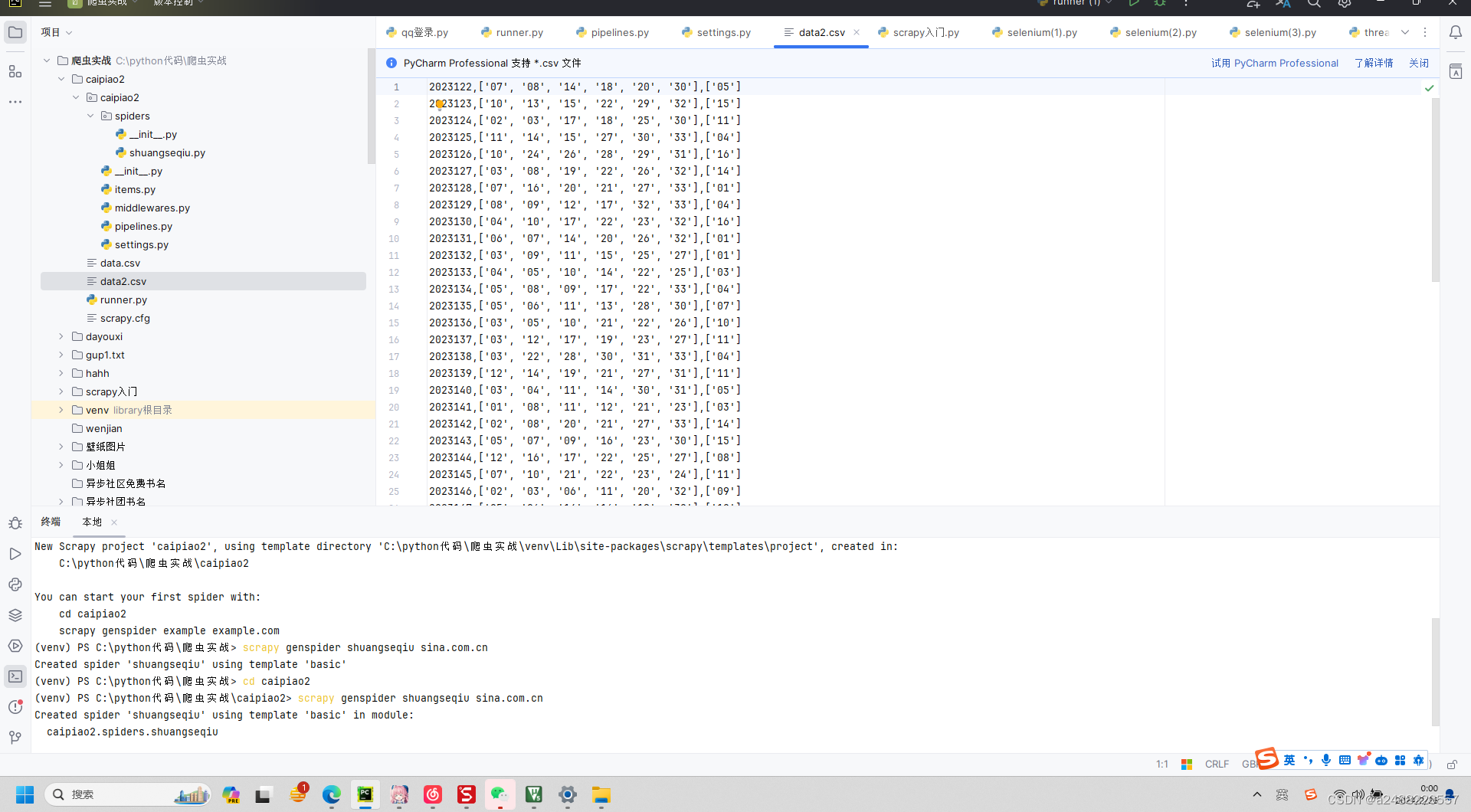
BeautifulSoup+xpath+re+css简单复习+新的scrapy的学习
1.BeautifulSoupsoup BeautifulSoup(html,html.parser)all_icosoup.find(class_"DivTable") 2.xpath trs resp.xpath("//tbody[idcpdata]/tr")
hong tr.xpath("./td[classchartball01 or classchartball20]/text()").extract()
这个意思是找…
python爬虫-数据解析BeautifulSoup
1、基本简介
BeautifulSoup简称bs4,BeautifulSoup和lxml一样是一个html的解析器,主要功能也是解析和提取数据。
BeautifulSoup和lxml类似,既可以解析本地文件也可以响应服务器文件。
缺点:效率没有lxml的效率高 。
优点:接口设…
作者开发的爬取妹子图片Python项目,值得你收藏拥有
最好的学习方法在于实践,学习编程语言Python,也是同样的道理。本文讲解自己开发的一个项目,实现爬取妹子图片,所用的Python知识点以及模块,可以关注参考作者公众号的Python语言合集。
—、前情介绍
1.1 涉及模块
本…

【Python lxml、BeautifulSoup和html.parser区别介绍】零基础也能轻松掌握的学习路线与参考资料
区别介绍
(1)lxml
lxml是Python的一个XML解析库,它基于libxml2和libxslt库构建,可以读取、操作和输出XML文档。lxml具有很强的性能和稳定性,在处理较大的XML文件时表现尤佳,并且支持XPath、CSS选择器等高…

爬取微博热榜并将其存储为csv文件
🙌秋名山码民的主页 😂oi退役选手,Java、大数据、单片机、IoT均有所涉猎,热爱技术,技术无罪 🎉欢迎关注🔎点赞👍收藏⭐️留言📝 获取源码,添加WX 目录 前言1.…
教女朋友学python系列--手把手教你用Python3进行网络爬虫
手把手教你用Python3进行网络爬虫 2018/6/11 星期一 整理
运行的环境: win10 x64 安装了anaconda3,基于Python3环境运行 使用Pycharm编程 1. 前期工作 安装 requests模块,API参考 安装 BeautifulSoup 4.2模块,API参考
2. 主要…
python3 爬虫相关学习9:BeautifulSoup 官方文档学习
目录
1 BeautifulSoup 官方文档
报错暂时保存
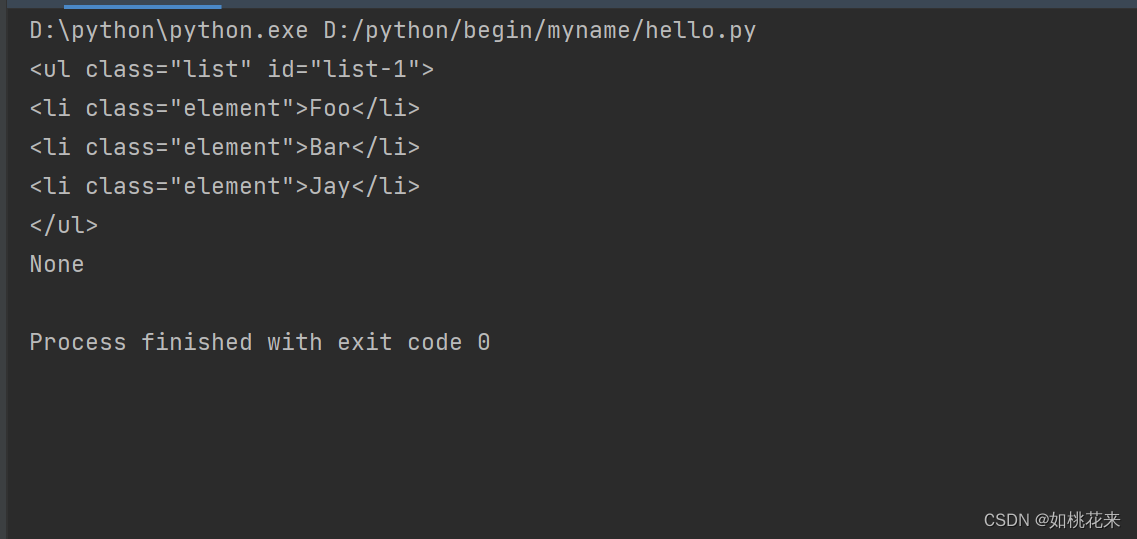
2 用bs 和 requests 打开 本地html的区别:代码里的一段html内容
2.1 代码和运行结果
2.2 用beautiful 打开 本地 html 文件
2.2.1 本地html文件
2.2.2 soup1BeautifulSoup(html1,"lxml")
2.3 用reque…

BeautifulSoup在数据采集中的应用
目录
一、BeautifulSoup库的安装和导入
二、HTML或XML文档的解析
1、直接将HTML文本字符串作为参数传递给BeautifulSoup函数:
2、 通过文件路径或URL加载HTML或XML文档:
三、导航和搜索
1、find()方法:查找文档中的某个元素。
2、 fin…

〖Python网络爬虫实战⑭〗- BeautifulSoup详讲
订阅:新手可以订阅我的其他专栏。免费阶段订阅量1000python项目实战 Python编程基础教程系列(零基础小白搬砖逆袭) 说明:本专栏持续更新中,目前专栏免费订阅,在转为付费专栏前订阅本专栏的,可以免费订阅付费…
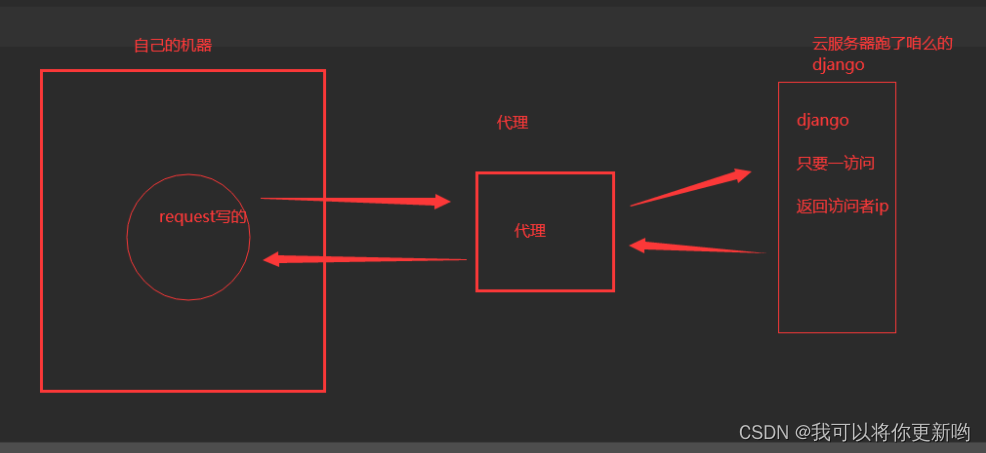
2-爬虫-代理池搭建、代理池使用(搭建django后端测试)、爬取某视频网站、爬取某视频网站、bs4介绍和遍历文档树
1 代理池搭建 2 代理池使用 2.1 搭建django后端测试
3 爬取某视频网站 4爬取某视频网站 5 bs4介绍和遍历文档树 1 代理池搭建
# ip代理-每个设备都会有自己的IP地址-电脑有ip地址---》访问一个网站---》访问太频繁---》封ip-收费:靠谱稳定--提供api-免费ÿ…

爬虫入门指南(1):学习爬虫的基础知识和技巧
文章目录 爬虫基础知识什么是爬虫?爬虫的工作原理爬虫的应用领域 爬虫准备工作安装Python安装必要的库和工具 网页解析与XPath网页结构与标签CSS选择器与XPathXpath 语法XPath的基本表达式:XPath的谓语(Predicate):XPa…

Python爬虫基础之BeautifulSoup
Python爬虫基础之BeautifulSoup一、BeautifulSoup基础功能1.1 CSS和前端常用标签及属性值1.2 HTML解析1.2.1 BeautifulSoup的find()和find_all()函数1.2.2 获取标签的子标签、兄弟标签、父标签1.2.2.1 子标签和其他后代标签1.2.2.2 兄弟标签1.2.2.3 父标签1.3 正则表达式和Beau…
第二章:25+ Python 数据操作教程(第二节Python安装 PYTHON 包)
Python 是数据科学和分析领域最流行的编程语言之一。它广泛用于初创公司和许多跨国组织的各种任务。这种编程语言的优点在于它是开源的,这意味着它可以免费使用,并且在世界各地拥有非常活跃的开发人员社区。Python 开发人员以包或模块的形式与其他 Python 用户分享他们的解决…

python爬虫实战——小红书
目录
1、博主页面分析
2、在控制台预先获取所有作品页的URL
3、在 Python 中读入该文件并做准备工作
4、处理图文类型作品
5、处理视频类型作品
6、异常访问而被中断的现象
7、完整参考代码 任务:在 win 环境下,利用 Python、webdriver、JavaS…
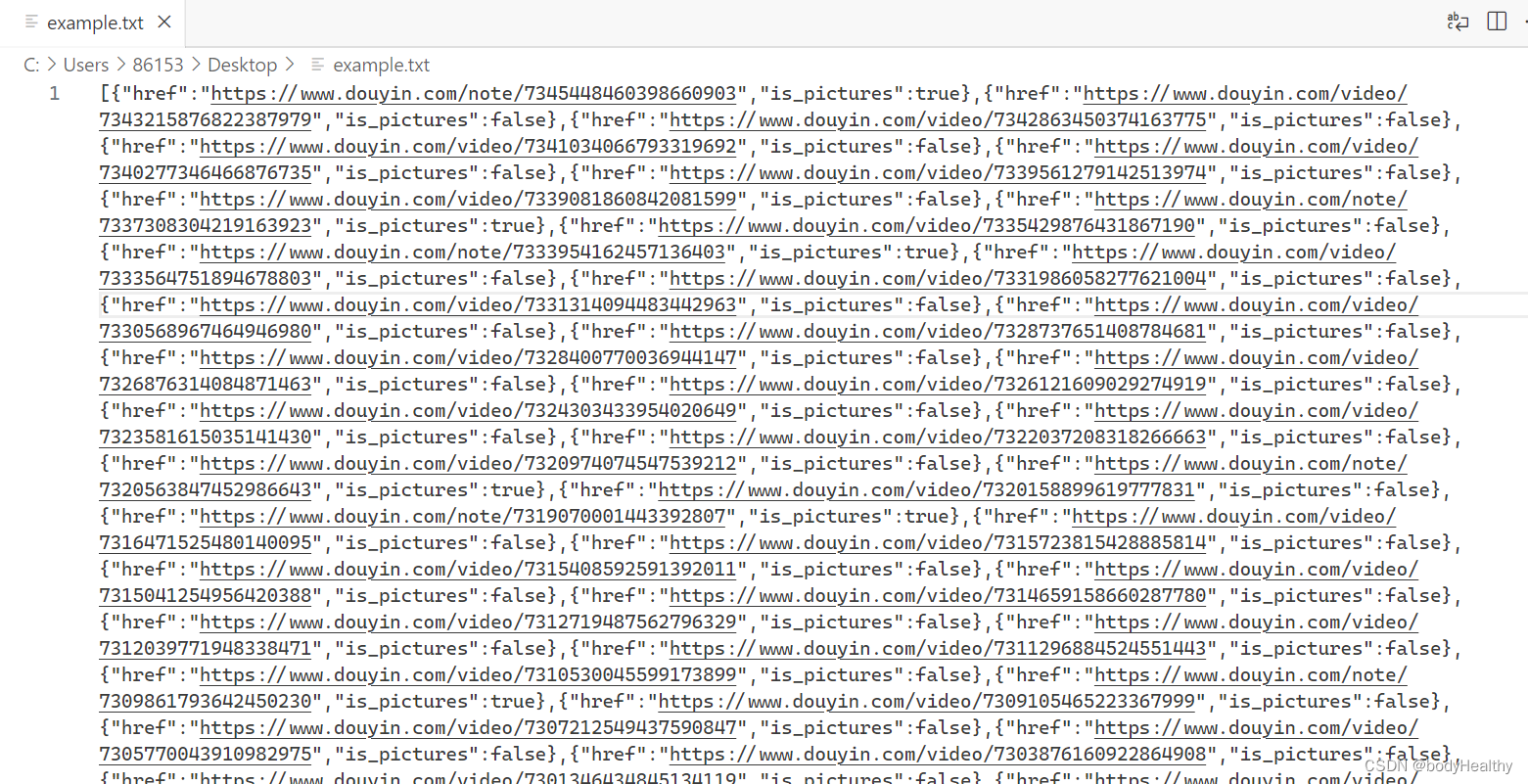
python爬虫实战——抖音
目录
1、分析主页作品列表标签结构
2、进入作品页前 判断作品是视频作品还是图文作品
3、进入视频作品页面,获取视频
4、进入图文作品页面,获取图片
5、完整参考代码
6、获取全部作品的一种方法 本文主要使用 selenium.webdriver(Firef…
3.2 Beautiful Soup 的使用
目录
一、Beautiful Soup 的简介
二、解析器
三、基本使用
四、节点选择器
1 选择元素
2 获取名称、属性、文本内容
五、方法选择器
1 find_all
传入 name 节点名
传入 attrs 属性
传入 text
2 find
六、CSS 选择器
1 实例
2 获取属性
3 获取文本
七、结语 一…

【BeautifulSoup】——05全栈开发——如桃花来
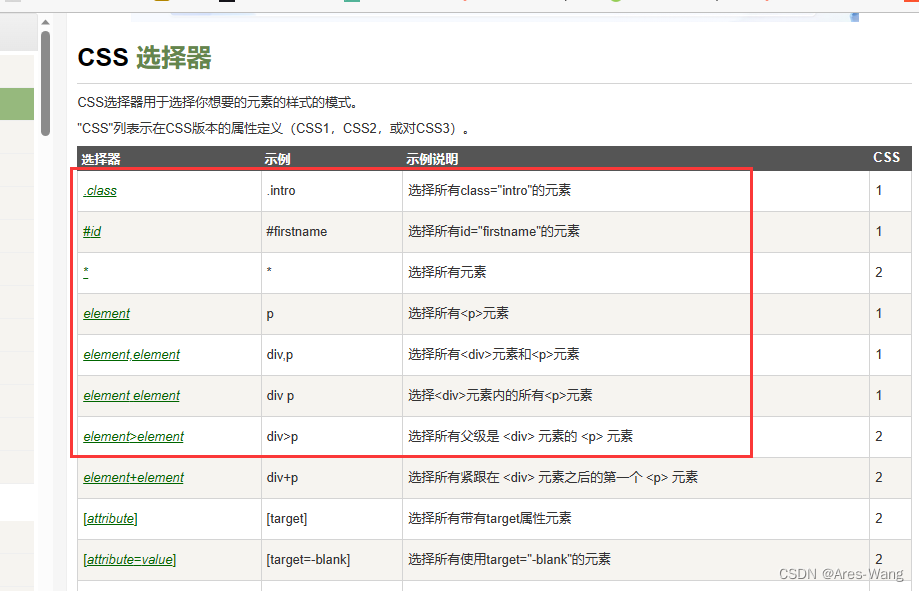
目录索引 介绍:解析库: 安装:pip install BeautifulSoup4pip install lxml 标签选择器:1.string属性:.name属性:获取标签中的属性值: 实用——标准选择器:使用find_all()根据标签名查…

什么是IP代理和爬虫技术?
博主猫头虎的技术世界 🌟 欢迎来到猫头虎的博客 — 探索技术的无限可能! 专栏链接: 🔗 精选专栏: 《面试题大全》 — 面试准备的宝典!《IDEA开发秘籍》 — 提升你的IDEA技能!《100天精通鸿蒙》 …

Python XPath解析html出现â解决方法 html出现#123;解决方法
前言
爬网页又遇到一个坑,老是出现乱码,查看html出现的是&#数字;这样的。
网上相关的“Python字符中出现&#的解决办法”又没有很好的解决,自己继续冲浪,费了一番功夫解决了。
这算是又加深了一下我对这些iso、Unicode编…
Python 学习——Python BeautifulSoup 库文档
目录 一、 Beautiful Soup 4.4.0 文档1.1 寻求帮助 二、 快速开始三、 安装 Beautiful Soup3.1 安装完成后的问题3.2 安装解析器 四、 如何使用五、 对象的种类5.1 Tag5.1.1 Name5.1.2 Attributes5.1.3 多值属性 5.2 可以遍历的字符串5.3 BeautifulSoup5.4 注释及特殊字符串 六…
python spider 爬虫 之 解析 xpath 、jsonpath、BeautifulSoup (三)
BeautifulSoup
简称:bs4
BeautifulSoup跟lxml 一样,是一个html文档的解析器,主要功能也是解析和提取数据 优缺点 缺点:效率没有lxml的效率高 优点:接口接口人性化,使用方便 延用了css选择器 安装Beautifu…
python爬虫自动采集并上传更新网站 requests wordpress_xmlrpc wordpress实战
爬虫用的 bs4requests
上传用的 wordpress_xmlrpc
#coded by 伊玛目的门徒
#codingutf-8
from wordpress_xmlrpc import Client, WordPressPost
from wordpress_xmlrpc.methods.posts import GetPosts, NewPost
from wordpress_xmlrpc.methods.users import GetUserInfo
imp…
第一章:最新版零基础学习 PYTHON 教程(第七节 - Python 中的语句、缩进和注释)
在这里,我们将讨论Python中的语句、Python中的缩进和Python中的注释。我们还将讨论 Python 语句、Python 缩进、Python 注释的不同规则和示例,以及“文档字符串”和“多行注释”之间的区别。
Python中的语句是什么
Python语句是Python 解释器可以执行的指令。Python 语言中…
【Python 爬虫之BeautifulSoup】零基础也能轻松掌握的学习路线与参考资料
BeautifulSoup是一种Python库,用于解析HTML和XML文档,并从中提取数据。它提供了Pythonic的解决方案来处理非结构化数据,因此可以轻松地从网页上提取数据。 使用BeautifulSoup编写爬虫,你可以自动化许多任务,比如数据抓…
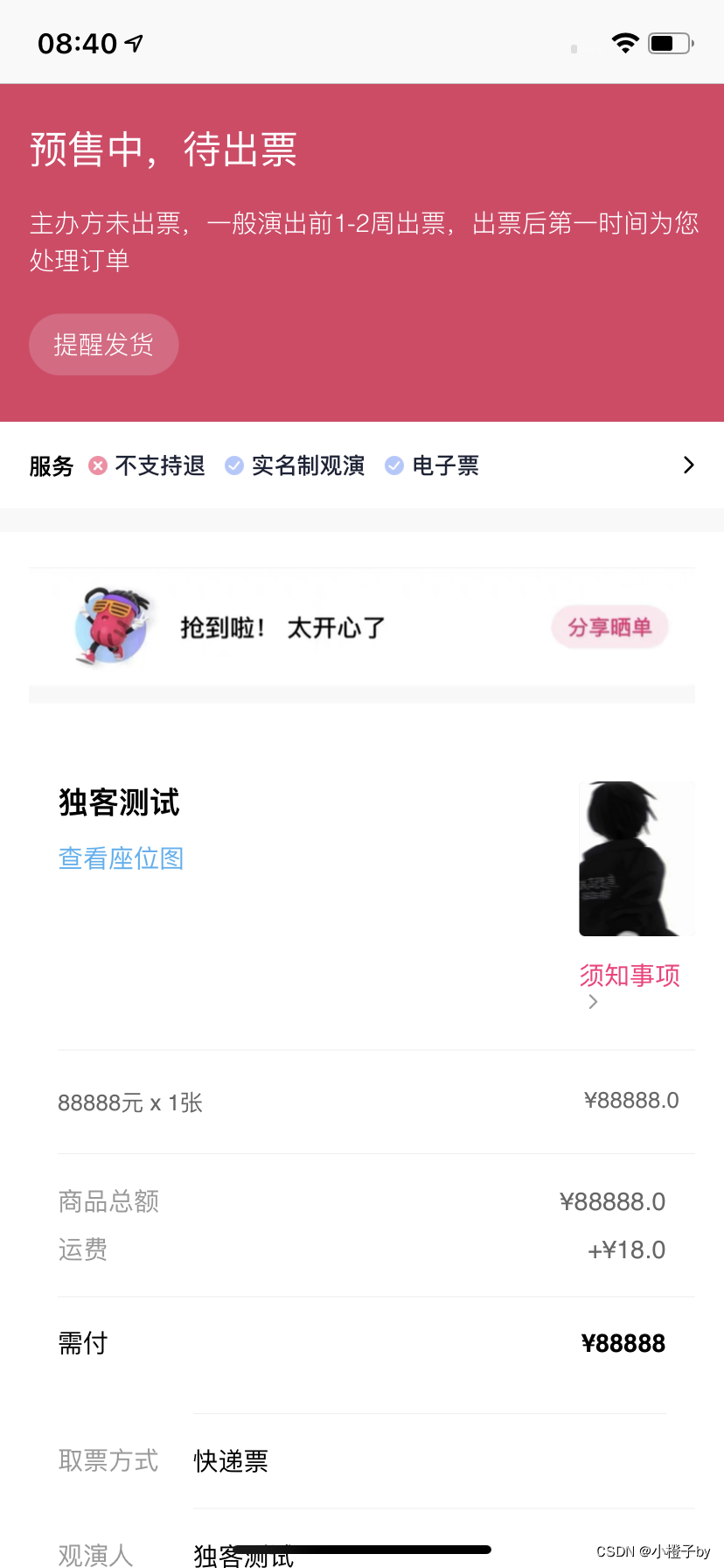
大麦订单生成器 大麦订单一键生成截图
1、能够一键的进行添加,生成的假订单是没有水印的,界面也很真实。
2、在软件中输入生成的信息,这里输入的是商品信息,选择生成的商品图片,最后生成即可。
新版大麦订单生成 图样式展示
这个样式图就是在大麦生成完…

如何获取美团的热门商品和服务
导语
美团是中国最大的生活服务平台之一,提供了各种各样的商品和服务,如美食、酒店、旅游、电影、娱乐等。如果你想了解美团的热门商品和服务,你可以使用爬虫技术来获取它们。本文将介绍如何使用Python和BeautifulSoup库来编写一个简单的爬虫…
第三章:最新版零基础学习 PYTHON 教程(第一节 - Python 运算符)
在Python编程中,运算符一般用于对值和变量进行操作。这些是用于逻辑和算术运算的标准符号。在本文中,我们将研究不同类型的Python 运算符。 运算符:这些是特殊符号。例如- + 、 * 、 / 等。操作数:它是应用运算符的值。目录
Python 中的运算符类型
Python 中的算术运算符…

Web Scraping指南: 使用Selenium和BeautifulSoup
在当今信息时代,数据是无处不在的宝贵资源。对于许多企业、研究人员以及开发者来说,从互联网上获取准确且有价值的数据变得越来越重要。而Web scraping(网络爬虫)技术则成为了实现这一目标的关键工具。
本篇文章将向您介绍一个高…
Python 之 Http 获取网页的 html 数据,并去掉 html 格式等相关信息
Python之 Http 获取网页的 html 数据,并去掉 html 格式等相关信息 目录
Python之 Http 获取网页的 html 数据,并去掉 html 格式等相关信息
快递单号批量查询教程,掌握包裹动态,让你成为物流达人!
亲爱的读者们,你是否曾经为了追踪快递包裹而烦恼?是否曾经为了查询多个快递单号而感到繁琐?现在,我们为你带来一个高效便捷的解决方案——快递单号批量查询教程!让你轻松掌握包裹动态,成为物流达人…
爬虫 | 正则、Xpath、BeautifulSoup示例学习
文章目录 📚import requests📚import re📚from lxml import etree📚from bs4 import BeautifulSoup📚小结 契机是课程项目需要爬取一份数据,于是在CSDN搜了搜相关的教程。在博主【朦胧的雨梦】主页学到很多…
通过关键字从百度中爬取相匹配图片,可以爬取多种也可以爬取一种图片
通过re、requests、urlib、BeautifulSoup、os模块实现从百度下载指定类别图片。包含代码逐行解析。
import re
# 进行http请求的第三方库
import requests
from urllib import error
# 解析HTML和XML文档的库
from bs4 import BeautifulSoup
import osnum 0
numPi 0
file
…
第三章:最新版零基础学习 PYTHON 教程(第五节 - Python 运算符—Python 中的赋值运算符)
运算符用于对值和变量执行操作。这些是执行算术、逻辑、按位计算的特殊符号。运算符运算的值称为操作数。
目录
(1) 赋值:该运算符用于将表达式右侧的值赋给左侧操作数。
Python3

利用爬虫技术自动化采集汽车之家的车型参数数据
导语
汽车之家是一个专业的汽车网站,提供了丰富的汽车信息,包括车型参数、图片、视频、评测、报价等。如果我们想要获取这些信息,我们可以通过浏览器手动访问网站,或者利用爬虫技术自动化采集数据。本文将介绍如何使用Python编写…
BeautifulSoup 用法详解 —— 安装与解析器
Beautiful Soup 4.4.0 文档: https://beautifulsoup.readthedocs.io/zh_CN/latest/
使用 BeautifulSoup 解析一段 HTML 代码,能够得到一个 BeautifulSoup 的对象。
1. 安装 Beautiful Soup 与 解析器
pip install beautifulsoup4 # 安装 Beautifu…
Python爬虫快速入门指南
引言:
网络爬虫是一种自动化程序,可以在互联网上搜集和提取数据。Python作为一种功能强大且易学的编程语言,成为了许多爬虫开发者的首选。本文将为你提供一个关于Python爬虫的快速入门指南,包括基本概念、工具和实际案例。
第一…
BeautifulSoup 用法详解 —— 对象的种类
Beautiful Soup 4.4.0 文档: https://beautifulsoup.readthedocs.io/zh_CN/latest/
Beautiful Soup 将复杂 HTML 文档转换成一个复杂的树形结构,每个节点都是 Python 对象,所有对象可以归纳为4种:Tag, NavigableString, Beautif…

python网络数据获取
文章目录1网络爬虫2网络爬虫的类型2.1通用网络爬虫2.1.12.1.22.2聚焦网络爬虫2.2.1 基于内容评价的爬行策略2.2.2 基于链接结构的爬行策略2.2.3基于增强学习的爬行策略2.2.4基于语境图的爬行策略2.3增量式网络爬虫深层网页爬虫3网络爬虫基本架构3.1URL管理模块3.2网页下载模块3…
Python3 HTML数据解析(lxml/BeautifulSoup/JsonPath)
Python3 HTML数据解析(lxml/BeautifulSoup/JsonPath) 本文由 Luzhuo 编写,转发请保留该信息. 原文: https://blog.csdn.net/Rozol/article/details/79968795 以下代码以Python3.6.1为例 Less is more! lxml
#!/usr/bin/env python
# codingutf-8
__author__ Luzhuo
__date…

【UCAS自然语言处理作业一】利用BeautifulSoup爬取中英文数据,计算熵,验证齐夫定律
文章目录 前言中文数据爬取爬取界面爬取代码 数据清洗数据分析实验结果 英文数据爬取爬取界面动态爬取 数据清洗数据分析实验结果 结论 前言
本文分别针对中文,英文语料进行爬虫,并在两种语言上计算其对应的熵,验证齐夫定律github: ShiyuNee…
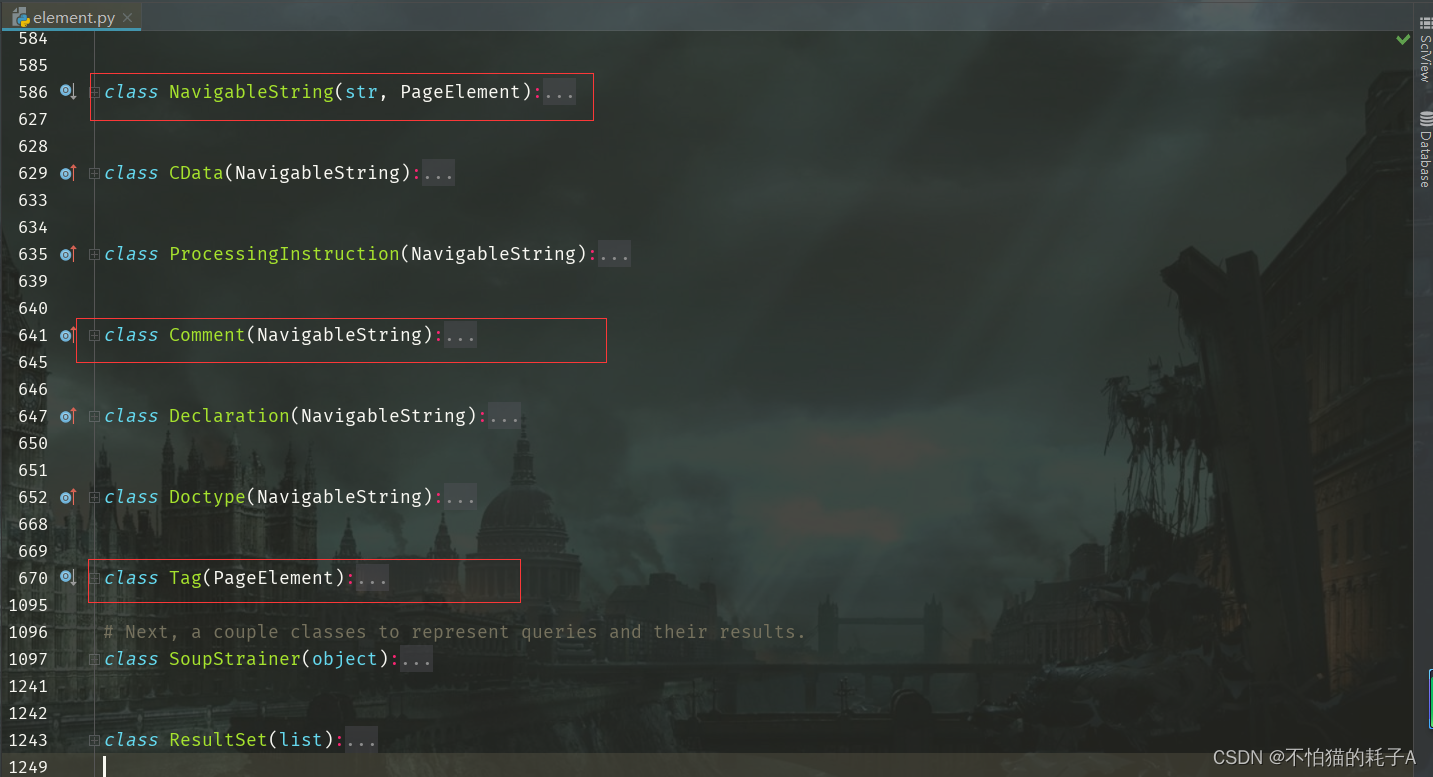
Python:BeautifulSoup库介绍
BeautifulSoup库介绍
1、BeautifulSoup是Python中的一个第三方库,其最主要的功能是处理HTML文档 ⑴查找HTML文档中的指定标签 ⑵获取HTML文档中指定标签的标签名、标签值、标签属性等 ⑶修改HTML文档中指定标签
2、BeautifulSoup库将HTML文档解析为一…
Python使用Beautiful Soup及解析html获取元素并提取内容值
Python使用Beautiful Soup及解析html获取元素并提取内容值 1. 包括解析获取标题2. 根据标签及id获取所有元素3. 根据标签及class获取所有元素4. 获取元素下的标签的值5. 获取元素下的parent及child的元素的值参考 1. 包括解析获取标题
2. 根据标签及id获取所有元素
3. 根据标…
【BeautifulSoup上】——05全栈开发——如桃花来
目录索引 介绍:解析库: 安装:pip install BeautifulSoup4pip install lxml 标签选择器:1.string属性:.name属性:获取标签中的属性值: 实用——标准选择器:使用find_all()根据标签名查…
【Python爬虫开发基础⑨】jsonpath和BeautifulSoup库概述及其对比
🚀个人主页:为梦而生~ 关注我一起学习吧! 💡专栏:python网络爬虫从基础到实战 欢迎订阅!后面的内容会越来越有意思~ 💡往期推荐: ⭐️首先,我们前面讲了多篇基础内容&…

XPath判断当前选中节点的元素类型 Python lxml判断当前Element的元素类型 爬虫爬取页面分元素类型提取纯文本
背景&前言
不知道你们做爬虫的时候,有没有碰到和我一样的情况:将页面提取成纯文本的时候,由于页面中各种链接、加粗字体等,直接提取会造成结果一坨一坨的,非常不规整。有时候还要自己对标题等元素进行修改&#x…
第五章:最新版零基础学习 PYTHON 教程—Python 字符串操作指南(第十节 Python——查找字符串中所有重复的字符)
给定一个字符串,找到所有彼此相似的重复字符。让我们看一下这个例子。
例子:
# 输入:你好
# 输出:好
输入字符串 = "你好"
字符索引 = 输入字符串.index("好")
输出字符 = 输入字符串[字符索引]
print(输出字符)# 输入:吴老师for吴老师
# 输出:空…
python spider 爬虫 之 解析 xpath 、jsonpath、BeautifulSoup (-)
Xpath 插件下载及安装
下载地址:https://chrome.zzzmh.cn/info/hgimnogjllphhhkhlmebbmlgjoejdpjl 安装xpath 如果下载的xpath后缀是crx 格式的, 直接改成zip格式,然后直接拖拽到上面的界面中便可, 查看是否安装成功,…

数据爬取(urllib+BeautifulSoup)
文章目录知识点总结爬虫步骤爬虫三要素爬虫注意事项python爬取技术学习网页抓取库Urllib网页解析库Beautifulsoup案例知识点总结 爬虫是一种按照一定规则,自动抓取互联网上网页中的相应信息的程序或脚本。 爬虫步骤
1.需求分析 2.找到要爬取信息的网站 3.下载reque…
Python 网页解析初级篇:BeautifulSoup库的入门使用
在Python的网络爬虫中,网页解析是一项重要的技术。而在众多的网页解析库中,BeautifulSoup库凭借其简单易用而广受欢迎。在本篇文章中,我们将学习BeautifulSoup库的基本用法。
一、BeautifulSoup的安装与基本使用
首先,我们需要使…
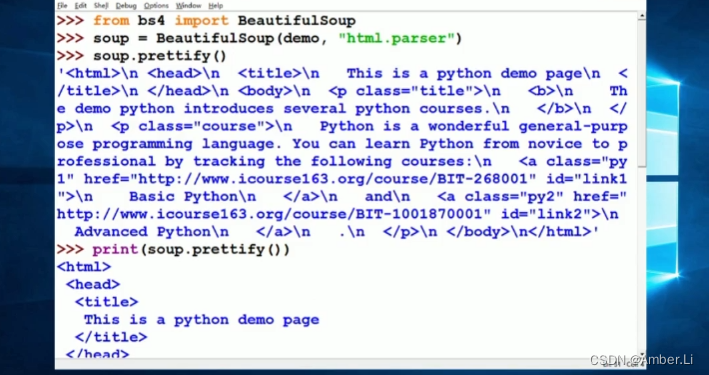
beautifulSoup 【HTML树解析库】基本知识
文章目录1. 文档地址2. 安装3. 使用4. 解析器5. 对象的种类6. 遍历6.1 下行遍历6.2 上行遍历6.3 平行遍历7. 格式化与编码7.1 格式化7.2 编码1. 文档地址
beautifulSoup4 文档
2. 安装
pip3 install beautifulsoup43. 使用
from bs4 import BeautifulSoupsoup BeautifulSo…

Python爬虫之美丽的汤——BeautifulSoup
本文概要
本篇文章主要介绍利用Python爬虫之美丽的汤——BeautifulSoup,适合练习爬虫基础同学,文中描述和代码示例很详细,干货满满,感兴趣的小伙伴快来一起学习吧! 是不是以为今天要教大家怎么做饭?确实&…
BeautifulSoup的使用与入门
1. 介绍
BeautifulSoup是用来从HTML、XML文档中提取数据的一个python库,安装如下:
pip install beautifulsoup4
它支持多种解析器,包括python标准库、lxml HTML解析器、lxml XML解析器、html5lib等。结合稳定性和速度,这里推荐使用lxml HT…
Python和BeautifulSoup库的魔力:解析TikTok视频页面
概述
短视频平台如TikTok已成为信息传播和电商推广的重要渠道。用户通过短视频分享生活、创作内容,吸引了数以亿计的观众,为企业和创作者提供了广阔的市场和宣传机会。然而,要深入了解TikTok上的视频内容以及用户互动情况,需要借…

多线程爬取中超全部2018赛季职业球员
本文旨在得到全部中超职业球员信息,之后可以用于数据分析(如多维度聚类球员类型)或者利用球员名列表对体育新闻分词,找出曝光度最高或者最低调的球员,亦或者用于开发体育游戏等等
首先:
继续爬虫球探网&a…
爬虫练习-获取imooc课程目录
代码:
from bs4 import BeautifulSoup
import requests
headers{
User-Agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:94.0) Gecko/20100101 Firefox/94.0,
}id371 #课程id
htmlrequests.get(https://coding.imooc.com/class/chapter/id.html#Anchor,head…
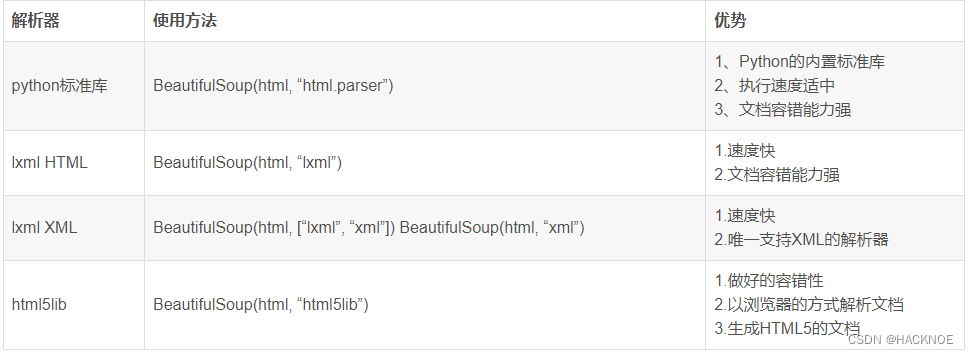
python从入门到精通(十六):python爬虫的BeautifulSoup4
python爬虫的BeautifulSoup4 BeautifulSoup4导入模块解析文件创建对象python解析器beautifulsoup对象的种类Tag获取整个标签获取标签里的属性和属性值Navigablestring 获取标签里的内容BeautifulSoup获取整个文档Comment输出的内容不包含注释符号BeautifulSoup文档遍历Beautifu…
R/S nomenclature for chiral center
Ideas:
Carbon atoms that are bound to four different atoms or groups are said to be asymmetric (chiral)
The bonds formed by an asymmetric carbon can be arranged in two different mirror images (stereoisomers) of each other
Stereoisomers are eith…
【Python】从入门到上头— 使用包、模块、安装第三方模块(7)
一.什么是模块
在Python中,一个.py文件就称之为一个模块(Module)。 模块好处?:
方便重用代码,写完一个通用的模块,可以在很多地方直接拿来用相同名字的函数和变量完全可以分别存在不同的模块中…
使用python实现第一个网络爬虫
什么是网络爬虫 网络爬虫(又被称为网页蜘蛛,网络机器人,在FOAF社区中间,更经常的称为网页追逐者),是一种按照一定的规则,自动地抓取万维网信息的程序或者脚本。另外一些不常使用的名字还有蚂蚁、…
第三章:最新版零基础学习 PYTHON 教程(第十三节 - Python 运算符—Python 中的运算符函数 - 套装2)
Python 中的运算符函数 - 套装1 本文将讨论更多功能。
1. setitem(ob, pos, val):- 该函数用于在容器中的 特定位置分配值。操作 – ob[pos] = val
2. delitem(ob, pos):- 该函数用于删除容器中 特定位置的值。 操作 – del ob[pos]
3. getitem(ob, pos)&#x
第七章:最新版零基础学习 PYTHON 教程—Python 列表(第六节 -在 Python 中清除列表的不同方法)
在本文中,我们将讨论在 Python 中清除列表的不同方法。Python 提供了许多不同的方法来清除列表,我们将在本文中讨论它们。
目录
在 Python 中从列表中删除的不同方法
使用 Python Listclear() 清除列表
python爬虫入门(六)BeautifulSoup使用
简单来说,BeautifulSoup 就是 Python 的一个 HTML 或 XML 的解析库,我们可以用它来方便地从网页中提取数据,官方的解释如下:
BeautifulSoup 提供一些简单的、Python 式的函数用来处理导航、搜索、修改分析树等功能。它是一个工具…
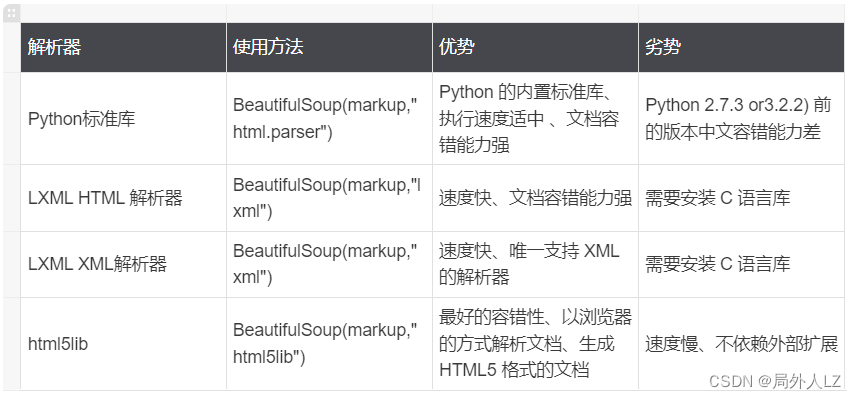
python 模块BeautifulSoup 从HTML或XML文件中提取数据
一、安装
Beautiful Soup 是一个HTML/XML的解析器,主要的功能也是如何解析和提取 HTML/XML 数据。 lxml 只会局部遍历,而Beautiful Soup 是基于HTML DOM的,会载入整个文档,解析整个DOM树,因此时间和内存开销都会大很多…
Python BeautifulSoup简介
1.BeautifulSoup简介 BeautifulSoup是一个可以从HTML或XML文件中提取数据的python库;它能够通过转换器实现惯用的文档导航、查找、修改文档的方式。 BeautifulSoup是一个基于re开发的解析库,可以提供一些强大的解析功能;使用BeautifulSoup能够…